Photo by Taylor Vick (Unsplash)
Linux networking can be confusing due to the wide range of technology stacks and tools in use, in addition to the complexity of the surrounding network environment. The configuration of bridges, bonds, VRFs or routes can be done programmatically, declaratively, manually or with automated with tools like ifupdown, ifupdown2, ifupdown-ng, iproute2, NetworkManager, systemd-networkd and others. Each of these tools use different formats and locations to store their configuration files. Netplan, a utility for easily configuring networking on a Linux system, is designed to unify and standardise how administrators interact with these underlying technologies. Starting from a YAML description of the required network interfaces and what each should be configured to do, Netplan will generate all the necessary configuration for your chosen tool.
In this article, we will provide an overview of how Ubuntu uses Netplan to manage Linux networking in a unified way. By creating a common interface across two disparate technology stacks, IT administrators benefit from a unified experience across both desktops and servers whilst retaining the unique advantages of the underlying tech.
But first, let s start with a bit of history and show where we are today.
The history of Netplan in Ubuntu
Starting with Ubuntu 16.10 and driven by the need to express network configuration in a common way across cloud metadata and other installer systems, we had the opportunity to switch to a network stack that integrates better with our dependency-based boot model. We chose systemd-networkd on server installations for its active upstream community and because it was already part of Systemd and therefore included in any Ubuntu base installation. It has a much better outlook for the future, using modern development techniques, good test coverage and CI integration, compared to the ifupdown tool we used previously. On desktop installations, we kept using NetworkManager due to its very good integration with the user interface.
Having to manage and configure two separate network stacks, depending on the Ubuntu variant in use, can be confusing, and we wanted to provide a streamlined user experience across any flavour of Ubuntu. Therefore, we introduced Netplan.io as a control layer above systemd-networkd and NetworkManager. Netplan takes declarative YAML files from /etc/netplan/ as an input and generates corresponding network configuration for the relevant network stack backend in /run/systemd/network/ or /run/NetworkManager/ depending on the system configuration. All while keeping full flexibility to control the underlying network stack in its native way if need be.
Who is using Netplan?
Recent versions of Netplan are available and ready to be installed on many distributions, such as Ubuntu, Fedora, RedHat Enterprise Linux, Debian and Arch Linux.
Ubuntu
As stated above, Netplan has been installed by default on Ubuntu systems since 2016 and is therefore being used by millions of users across multiple long-term support versions of Ubuntu (18.04, 20.04, 22.04) on a day-to-day basis. This covers Ubuntu server scenarios primarily, such as bridges, bonding, VLANs, VXLANs, VRFs, IP tunnels or WireGuard tunnels, using systemd-networkd as the backend renderer.
On Ubuntu desktop systems, Netplan can be used manually through its declarative YAML configuration files, and it will handle those to configure the NetworkManager stack. Keep reading to get a glimpse of how this will be improved through automation and integration with the desktop stack in the future.
Cloud
It might not be as obvious, but many people have been using Netplan without knowing about it when configuring a public cloud instance on AWS, Google Cloud or elsewhere through cloud-init. This is because cloud-init s Networking Config Version 2 is a passthrough configuration to Netplan, which will then set up the underlying network stack on the given cloud instance. This is why Netplan is also a key package on the Debian distribution, for example, as it s being used by default on Debian cloud images, too.
Our vision for Linux networking
We know that Linux networking can be a beast, and we want to keep simple things simple. But also allow for custom setups of any complexity. With Netplan, the day-to-day networking needs are covered through easily comprehensible and nicely documented YAML files, that describe the desired state of the local network interfaces, which will be rendered into corresponding configuration files for the relevant network stack and applied at (re-)boot or at runtime, using the netplan apply CLI. For example /etc/netplan/lan.yaml:
Having a single source of truth for network configuration is also important for administrators, so they do not need to understand multiple network stacks, but can rely on the declarative data given in /etc/netplan/ to configure a system, independent of the underlying network configuration backend. This is also very helpful to seed the initial network configuration for new Linux installations, for example through installation systems such as Subiquity, Ubuntu s desktop installer or cloud-init across the public and private clouds.
In addition to describing and applying network configuration, the netplan status CLI can be used to query relevant data from the underlying network stack(s), such as systemd-networkd, NetworkManager or iproute2, and present them in a unified way.
At the Netplan project we strive for very high test automation and coverage with plenty of unit tests, integration tests and linting steps, across multiple Linux distros, which gives high confidence in also supporting more advanced networking use cases, such as Open vSwitch or SR-IOV network virtualization, in addition to normal wired (static IP, DHCP, routing), wireless (e.g. wwan modems, WPA2/3 connections, WiFi hotspot, controlling the regulatory domain, ) and common server scenarios.
Should there ever be a scenario that is not covered by Netplan natively, it allows for full flexibility to control the underlying network stack directly through systemd override configurations or NetworkManager passthrough settings in addition to having manual configuration side-by-side with interfaces controlled through Netplan.
The future of Netplan desktop integration
On workstations, the most common scenario is for end users to configure NetworkManager through its user interface tools, instead of driving it through Netplan s declarative YAML files, which makes use of NetworkManager s native configuration files. To avoid Netplan just handing over control to NetworkManager on such systems, we re working on a bidirectional integration between NetworkManager and Netplan to further improve the single source of truth use case on Ubuntu desktop installations.
Netplan is shipping a libnetplan library that provides an API to access Netplan s parser and validation internals, that can be used by NetworkManager to write back a network interface configuration. For instance, configuration given through NetworkManager s UI tools or D-Bus API can be exported to Netplan s native YAML format in the common location at /etc/netplan/. This way, administrators just need to care about Netplan when managing a fleet of Desktop installations. This solution is currently being used in more confined environments, like Ubuntu Core, when using the NetworkManager snap, and we will deliver it to generic Ubuntu desktop systems in 24.04 LTS.
In addition to NetworkManager, libnetplan can also be used to integrate with other tools in the networking space, such as cloud-init for improved validation of user data or installation systems when seeding new Linux images.
Conclusion
Overall, Netplan can be considered to be a good citizen within a network environment that plays hand-in-hand with other networking tools and makes it easy to control modern network stacks, such as systemd-networkd or NetworkManager in a common, streamlined and declarative way. It provides a single source of truth to network administrators about the network state, while keeping simple things simple, but allowing for arbitrarily complex custom setups. If you want to learn more, feel free to follow our activities on Netplan.io, GitHub, Launchpad, IRC or our Netplan Developer Diaries blog on discourse.
I have several TB worth of family photos, videos, and other data. This needs to be backed up and archived.
Backups and archives are often thought of as similar. And indeed, they may be done with the same tools at the same time. But the goals differ somewhat:
Backups are designed to recover from a disaster that you can fairly rapidly detect.
Archives are designed to survive for many years, protecting against disaster not only impacting the original equipment but also the original person that created them.
Reflecting on this, it implies that while a nice ZFS snapshot-based scheme that supports twice-hourly backups may be fantastic for that purpose, if you think about things like family members being able to access it if you are incapacitated, or accessibility in a few decades time, it becomes much less appealing for archives. ZFS doesn t have the wide software support that NTFS, FAT, UDF, ISO-9660, etc. do.
This post isn t about the pros and cons of the different storage media, nor is it about the pros and cons of cloud storage for archiving; these conversations can readily be found elsewhere. Let s assume, for the point of conversation, that we are considering BD-R optical discs as well as external HDDs, both of which are too small to hold the entire backup set.
What would you use for archiving in these circumstances?
Establishing goals
The goals I have are:
Archives can be restored using Linux or Windows (even though I don t use Windows, this requirement will ensure the broadest compatibility in the future)
The archival system must be able to accommodate periodic updates consisting of new files, deleted files, moved files, and modified files, without requiring a rewrite of the entire archive dataset
Archives can ideally be mounted on any common OS and the component files directly copied off
Redundancy must be possible. In the worst case, one could manually copy one drive/disc to another. Ideally, the archiving system would automatically track making n copies of data.
While a full restore may be a goal, simply finding one file or one directory may also be a goal. Ideally, an archiving system would be able to quickly tell me which discs/drives contain a given file.
Ideally, preserves as much POSIX metadata as possible (hard links, symlinks, modification date, permissions, etc). However, for the archiving case, this is less important than for the backup case, with the possible exception of modification date.
Must be easy enough to do, and sufficiently automatable, to allow frequent updates without error-prone or time-consuming manual hassle
I would welcome your ideas for what to use. Below, I ll highlight different approaches I ve looked into and how they stack up.
Basic copies of directories
The initial approach might be one of simply copying directories across. This would work well if the data set to be archived is smaller than the archival media. In that case, you could just burn or rsync a new copy with every update and be done. Unfortunately, this is much less convenient with data of the size I m dealing with. rsync is unavailable in that case. With some datasets, you could manually design some rsyncs to store individual directories on individual devices, but that gets unwieldy fast and isn t scalable.
You could use something like my datapacker program to split the data across multiple discs/drives efficiently. However, updates will be a problem; you d have to re-burn the entire set to get a consistent copy, or rely on external tools like mtree to reflect deletions. Not very convenient in any case.
So I won t be using this.
tar or zip
While you can split tar and zip files across multiple media, they have a lot of issues. GNU tar s incremental mode is clunky and buggy; zip is even worse. tar files can t be read randomly, making it extremely time-consuming to extract just certain files out of a tar file.
The only thing going for these formats (and especially zip) is the wide compatibility for restoration.
dar
Here we start to get into the more interesting tools. Dar is, in my opinion, one of the best Linux tools that few people know about. Since I first wrote about dar in 2008, it s added some interesting new features; among them, binary deltas and cloud storage support. So, dar has quite a few interesting features that I make use of in other ways, and could also be quite helpful here:
Dar can both read and write files sequentially (streaming, like tar), or with random-access (quick seek to extract a subset without having to read the entire archive)
Dar can apply compression to individual files, rather than to the archive as a whole, faciliting both random access and resilience (corruption in one file doesn t invalidate all subsequent files). Dar also supports numerous compression algorithms including gzip, bzip2, xz, lzo, etc., and can omit compressing already-compressed files.
The end of each dar file contains a central directory (dar calls this a catalog). The catalog contains everything necessary to extract individual files from the archive quickly, as well as everything necessary to make a future incremental archive based on this one. Additionally, dar can make and work with isolated catalogs a file containing the catalog only, without data.
Dar can split the archive into multiple pieces called slices. This can best be done with fixed-size slices ( slice and first-slice options), which let the catalog regord the slice number and preserves random access capabilities. With the execute option, dar can easily wait for a given slice to be burned, etc.
Dar normally stores an entire new copy of a modified file, but can optionally store an rdiff binary delta instead. This has the potential to be far smaller (think of a case of modifying metadata for a photo, for instance).
Additionally, dar comes with a dar_manager program. dar_manager makes a database out of dar catalogs (or archives). This can then be used to identify the precise archive containing a particular version of a particular file.
All this combines to make a useful system for archiving. Isolated catalogs are tiny, and it would be easy enough to include the isolated catalogs for the entire set of archives that came before (or even the dar_manager database file) with each new incremental archive. This would make restoration of a particular subset easy.
The main thing to address with dar is that you do need dar to extract the archive. Every dar release comes with source code and a win64 build. dar also supports building a statically-linked Linux binary. It would therefore be easy to include win64 binary, Linux binary, and source with every archive run. dar is also a part of multiple Linux and BSD distributions, which are archived around the Internet. I think this provides a reasonable future-proofing to make sure dar archives will still be readable in the future.
The other challenge is user ability. While dar is highly portable, it is fundamentally a CLI tool and will require CLI abilities on the part of users. I suspect, though, that I could write up a few pages of instructions to include and make that a reasonably easy process. Not everyone can use a CLI, but I would expect a person that could follow those instructions could be readily-enough found.
One other benefit of dar is that it could easily be used with tapes. The LTO series is liked by various hobbyists, though it could pose formidable obstacles to non-hobbyists trying to aceess data in future decades. Additionally, since the archive is a big file, it lends itself to working with par2 to provide redundancy for certain amounts of data corruption.
git-annex
git-annex is an interesting program that is designed to facilitate managing large sets of data and moving it between repositories. git-annex has particular support for offline archive drives and tracks which drives contain which files.
The idea would be to store the data to be archived in a git-annex repository. Then git-annex commands could generate filesystem trees on the external drives (or trees to br burned to read-only media).
In a post about using git-annex for blu-ray backups, an earlier thread about DVD-Rs was mentioned.
This has a few interesting properties. For one, with due care, the files can be stored on archival media as regular files. There are some different options for how to generate the archives; some of them would place the entire git-annex metadata on each drive/disc. With that arrangement, one could access the individual files without git-annex. With git-annex, one could reconstruct the final (or any intermediate) state of the archive appropriately, handling deltions, renames, etc. You would also easily be able to know where copies of your files are.
The practice is somewhat more challenging. Hundreds of thousands of files what I would consider a medium-sized archive can pose some challenges, running into hours-long execution if used in conjunction with the directory special remote (but only minutes-long with a standard git-annex repo).
Ruling out the directory special remote, I had thought I could maybe just work with my files in git-annex directly. However, I ran into some challenges with that approach as well. I am uncomfortable with git-annex mucking about with hard links in my source data. While it does try to preserve timestamps in the source data, these are lost on the clones. I wrote up my best effort to work around all this.
In a forum post, the author of git-annex comments that I don t think that CDs/DVDs are a particularly good fit for git-annex, but it seems a couple of users have gotten something working. The page he references is Managing a large number of files archived on many pieces of read-only medium. Some of that discussion is a bit dated (for instance, the directory special remote has the importtree feature that implements what was being asked for there), but has some interesting tips.
git-annex supplies win64 binaries, and git-annex is included with many distributions as well. So it should be nearly as accessible as dar in the future. Since git-annex would be required to restore a consistent recovery image, similar caveats as with dar apply; CLI experience would be needed, along with some written instructions.
Bacula and BareOS
Although primarily tape-based archivers, these do also also nominally support drives and optical media. However, they are much more tailored as backup tools, especially with the ability to pull from multiple machines. They require a database and extensive configuration, making them a poor fit for both the creation and future extractability of this project.
Conclusions
I m going to spend some more time with dar and git-annex, testing them out, and hope to write some future posts about my experiences.
I wrote the Ruby bindings for the Enquo Project, my attempt to bring queryable encryption to all databases, using the Rutie library.
Recently, I ve rewritten the bindings to use Magnus instead, and I thought I d put down my thoughts about the whole situation.
The Story So Far
The Enquo Project core cryptography is all written in Rust, as seems to be the vogue these days.
Rust is fast, safe, and easily interoperable with most of the rest of the modern software development ecosystem, making it a good choice as a language to implement the cryptographic primitives that Enquo needs, like Order-Revealing Encryption.
Of course, since not everyone writes their applications in Rust, we need to provide the functionality of the Enquo client in the languages that people do use, such as Ruby, Python, and so on.
Since re-writing all that cryptographic code in a myriad of languages would be tedious and error-prone, we instead provide bindings to the core Rust code.
These are just thin shims of code that translate the data types and function calls between Rust and the target language.
Wrong sort of shim, but canned language bindings would be handy
As I m most familiar with Ruby and its development ecosystem (particularly Ruby on Rails), it was natural that I d make Ruby bindings for Enquo as my first target.
Rummaging around, it seemed that Rutie was a good library to use, so off I went.
What are Rutie and Magnus, Anyway?
Both libraries share the same goal: provide the ability to write some Rust code, run that through a compiler, and produce something that can be loaded by the Ruby interpreter and used just like any other Ruby class.
They re both fairly high level interfaces, trying to abstract away much of the gory details, and do a lot of the common heavy lifting that can make writing bindings fiddly and annoying.
Things like mapping data types (like strings and integers) between Rust data types and the closest equivalents in Ruby.
This mapping never goes perfectly smoothly.
For example, Ruby integers don t have a fixed range of values they can represent you can store a huge number like 2256 more-or-less as easily as you can the number 12.
But Rust, being a lower-level language, only has a set of integer types that have fixed boundaries, like the u32 type, which can only store integers between zero and about four billion (232 - 1, to be precise).
There s also lots of little things that need to be just right, also, like translating the different memory management approaches of the languages, and dealing with a myriad of fiddly little issues like passing arguments and return values in and out of method calls, helpers for defining classes and methods (and pointing to the correct Rust functions), and so on.
This is what I imagine it looks like inside these libraries
(Herv Cozanet / Wikimedia Commons, CC-BY-SA)
All in all, these libraries are fairly significant pieces of work, and I m mighty glad that someone else has taken on the job of building (and maintaining!) them.
So Why the Change?
Good question.
It s important to say at the outset that there s nothing particularly wrong with Rutie.
I found using Rutie to be very straightforward, and the Ruby bindings came together very quickly and easily.
If someone chose to use Rutie for their project, I m sure they d have a good experience.
What made me take the time to rewrite using Magnus was a set of a few tiny things, which together gave me enough of a shove to do the work.
Firstly, I d had a hiccup with Rutie s support of newer versions of Ruby, particularly 3.2 (PR).
Also, I d hit a couple of segfault issues, which were ultimately caused by Ruby garbage-collecting data out from underneath me.
These were ultimately my fault, of course, but Rutie wasn t helping me out in avoiding the problems in the first place.
Finally, while Rutie helped translate data types, there was still a bit of boilerplate and ugliness that needed to be included.
This wasn t a showstopper, but I m appreciating the extra smoothness that Magnus provides here.
As an example, here s what s required in Rutie to get native Rust data types from Ruby method parameters (and the self reference to the current object):
fn enquo_field_decrypt_text(ciphertext_obj: RString, context_obj: RString) -> RString
let ciphertext = ciphertext_obj.to_str_unchecked();
let context = context_obj.to_vec_u8_unchecked();
let field = rbself.get_data(&*FIELD_WRAPPER);
// etc etc etc
The equivalent in Magnus is just the function signature:
You can also see there that Magnus signals an exception via the Result return value, while Rutie s approach to raising an exception involves poking the Ruby VM directly, which always struck me as a bit ugly.
There are several other minor things in Magnus (like its cleaner approach to wrapping structs so they can be stored in Ruby objects) that I m appreciating, too.
Never discount the power of ergonomics for making a happy developer.
The End Result
I spent a bit over half of last weekend doing the rewrite maybe ten hours of so.
Since Magnus did more type checking and data validation, and its approach to error handling was smoother, I took the opportunity to rewrite a bunch of Ruby wrapper code I d written (which just existed to check things like ranges of values and string encodings) into Rust, as well.
To make sure that the conversion was accurate, I added a heap more unit tests to the bindings.
I also took the opportunity to restructure the codebase to split the code for the different Ruby classes into separate files, which I hadn t done initially as the code had originally accreted, rather than being purposefully written.
All up, though, my rewrite ended up removing over 60 lines (excluding the extra specs I added):
Considering that I was translating from a higher level language into a lower level one, the removal of so much code is quite remarkable.
Magnus was able to automagically replace rather a lot of raise ArgumentError if something.isnt_right code in those .rb files.
So, in conclusion, if you, too, are building Ruby extensions in Rust, while Rutie is a solid choice (and you probably should stick with it if you re already using it), I highly recommend giving Magnus a look for your next extension.
Welcome to the March 2023 report from the Reproducible Builds project.
In these reports we outline the most important things that we have been up to over the past month. As a quick recap, the motivation behind the reproducible builds effort is to ensure no malicious flaws have been introduced during compilation and distributing processes. It does this by ensuring identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised.
If you are interested in contributing to the project, please do visit our Contribute page on our website.
News
There was progress towards making the Go programming language reproducible this month, with the overall goal remaining making the Go binaries distributed from Google and by Arch Linux (and others) to be bit-for-bit identical. These changes could become part of the upcoming version 1.21 release of Go. An issue in the Go issue tracker (#57120) is being used to follow and record progress on this.
Arnout Engelen updated our website to add and update reproducibility-related links for NixOS to reproducible.nixos.org. []. In addition, Chris Lamb made some cosmetic changes to our presentations and resources page. [][]
Intel published a guide on how to reproducibly build their Trust Domain Extensions (TDX) firmware. TDX here refers to an Intel technology that combines their existing virtual machine and memory encryption technology with a new kind of virtual machine guest called a Trust Domain. This runs the CPU in a mode that protects the confidentiality of its memory contents and its state from any other software.
A reproducibility-related bug from early 2020 in the GNU GCC compiler as been fixed. The issues was that if GCC was invoked via the as frontend, the -ffile-prefix-map was being ignored. We were tracking this in Debian via the build_path_captured_in_assembly_objects issue. It has now been fixed and will be reflected in GCC version 13.
Holger Levsen will present at foss-north 2023 in April of this year in Gothenburg, Sweden on the topic of Reproducible Builds, the first ten years.
Anthony Andreoli, Anis Lounis, Mourad Debbabi and Aiman Hanna of the Security Research Centre at Concordia University, Montreal published a paper this month entitled On the prevalence of software supply chain attacks: Empirical study and investigative framework:
Software Supply Chain Attacks (SSCAs) typically compromise hosts through trusted but infected software. The intent of this paper is twofold: First, we present an empirical study of the most prominent software supply chain attacks and their characteristics. Second, we propose an investigative framework for identifying, expressing, and evaluating characteristic behaviours of newfound attacks for mitigation and future defense purposes. We hypothesize that these behaviours are statistically malicious, existed in the past, and thus could have been thwarted in modernity through their cementation x-years ago. []
Mattia Rizzolo is asking everyone in the community to save the date for the 2023 s Reproducible Builds summit which will take place between October 31st and November 2nd at Dock Europe in Hamburg, Germany. Separate announcement(s) to follow. []
ahojlm posted an message announcing a new project which is the first project offering bootstrappable and verifiable builds without any binary seeds. That is to say, a way of providing a verifiable path towards trusted software development platform without relying on pre-provided binary code in order to prevent against various forms of compiler backdoors. The project s homepage is hosted on Tor (mirror).
The minutes and logs from our March 2023 IRC meeting have been published. In case you missed this one, our next IRC meeting will take place on Tuesday 25th April at 15:00 UTC on #reproducible-builds on the OFTC network.
and as a Valentines Day present, Holger Levsen wrote on his blog on 14th February to express his thanks to OSUOSL for their continuous support of reproducible-builds.org. []
Debian
Vagrant Cascadian developed an easier setup for testing debian packages which uses sbuild s unshare mode along and reprotest, our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. []
Over 30 reviews of Debian packages were added, 14 were updated and 7 were removed this month, all adding to our knowledge about identified issues. A number of issues were updated, including the Holger Levsen updating build_path_captured_in_assembly_objects to note that it has been fixed for GCC 13 [] and Vagrant Cascadian added new issues to mark packages where the build path is being captured via the Rust toolchain [] as well as new categorisation for where virtual packages have nondeterministic versioned dependencies [].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In March, the following changes were made by Holger Levsen:
Add/update openQA configuration [], and use the actual timestamp for openQA builds [].
Moved adding the user to the docker group from the janitor_setup_worker script to the (more general) update_jdn.sh script. []
Use the (short-term) reproducible source when generating live-build images. []
diffoscope development
diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats as well. This month, Mattia Rizzolo released versions 238, and Chris Lamb released versions 239 and 240. Chris Lamb also made the following changes:
Fix compatibility with PyPDF 3.x, and correctly restore test data. []
Rework PDF annotation handling into a separate method. []
In addition, Holger Levsen performed a long-overdue overhaul of the Lintian overrides in the Debian packaging [][][][], and Mattia Rizzolo updated the packaging to silence an include_package_data=True [], fixed the build under Debian bullseye [], fixed tool name in a list of tools permitted to be absent during package build tests [] and as well as documented sending out an email upon [].
In addition, Vagrant Cascadian updated the version of GNU Guix to 238 [ and 239 []. Vagrant also updated reprotest to version 0.7.23. []
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
I had a go at trying to figure out how to generate arbitrary MIDI events and
send them out over a JACK MIDI channel.
Setting up JACK and Pipewire
Pipewire has a JACK interface, which in theory means one could use JACK clients
out of the box without extra setup.
In practice, one need to tell JACK clients which set of libraries to use to
communicate to servers, and Pipewire's JACK server is not the default choice.
To tell JACK clients to use Pipewire's server, you can either:
on a client-by-client basis, wrap the commands with
pw-jack
to change the system default: cp /usr/share/doc/pipewire/examples/ld.so.conf.d/pipewire-jack-*.conf /etc/ld.so.conf.d/ and run ldconfig (see the Debian wiki for details)
Programming with JACK
Python has a JACK client library
that worked flawlessly for me so far.
Everything with JACK is designed around minimizing latency. Everything happens
around a callback that gets called form a separate thread, and which gets a
buffer to fill with events.
All the heavy processing needs to happen outside the callback, and the callback
is only there to do the minimal amount of work needed to shovel the data your
application produced into JACK channels.
Generating MIDI messages
The Mido library can be used to parse
and create MIDI messages and it also worked flawlessly for me so far.
One needs to study a bit what kind of MIDI message one needs to generate (like
"note on", "note off", "program change") and what arguments they get.
It also helps to read about the General MIDI
standard which defines mappings between well-known instruments and channels and
instrument numbers in MIDI messages.
A timed message queue
To keep a queue of events that happen over time, I implemented a Delta
List that indexes events by
their future frame number.
I called the humble container for my audio experiments pyeep
and here's my delta list implementation.
A JACK player
The simple JACK MIDI player backend is also in pyeep.
It needs to protect the delta list with a mutex since we are working across
thread boundaries, but it tries to do as little work under lock as possible, to
minimize the risk of locking the realtime thread for too long.
The play method converts delays in seconds to frame counts, and the
on_process callback moves events from the queue to the jack output.
Here's an example script that plays a simple drum pattern:
#!/usr/bin/python3# Example JACK midi event generator## Play a drum pattern over JACKimporttimefrompyeep.jackmidiimportMidiPlayer# See:# https://soundprogramming.net/file-formats/general-midi-instrument-list/# https://www.pgmusic.com/tutorial_gm.htmDRUM_CHANNEL=9withMidiPlayer("pyeep drums")asplayer:beat:int=0whileTrue:player.play("note_on",velocity=64,note=35,channel=DRUM_CHANNEL)player.play("note_off",note=38,channel=DRUM_CHANNEL,delay_sec=0.5)ifbeat==0:player.play("note_on",velocity=100,note=38,channel=DRUM_CHANNEL)player.play("note_off",note=36,channel=DRUM_CHANNEL,delay_sec=0.3)ifbeat+1==2:player.play("note_on",velocity=100,note=42,channel=DRUM_CHANNEL)player.play("note_off",note=42,channel=DRUM_CHANNEL,delay_sec=0.3)beat=(beat+1)%4time.sleep(0.3)
Running the example
I ran the jack_drums script, and of course not much happened.
First I needed a MIDI synthesizer. I installed
fluidsynth, and ran it on the
command line with no arguments. it registered with JACK, ready to do its thing.
Then I connected things together. I used
qjackctl, opened the graph view, and
connected the MIDI output of "pyeep drums" to the "FLUID Synth input port".
fluidsynth's output was already automatically connected to the audio card and I
started hearing the drums playing!
As I am sure everyone is aware, there is a growing interest in [SBOMs] as a
way of improving software security and resilience. In the last two years, the
US through the Exec Order, the EU through the proposed Cyber Resilience Act
(CRA) and this month the UK has issued a consultation paper looking at
software security and SBOMs appear very prominently in each
publication. []
Tim Retout wrote a blog post discussing AlmaLinux in the context of CentOS, RHEL and supply-chain security in general []:
Alma are generating and publishing Software Bill of Material (SBOM) files for
every package; these are becoming a requirement for all software sold to the
US federal government. What s more, they are sending these SBOMs to a third
party (CodeNotary) who store them in some sort of
Merkle tree system to make it
difficult for people to tamper with later. This should theoretically allow
end users of the distribution to verify the supply chain of the packages they
have installed?
Debian
Vagrant Cascadian noted that the Debian bookworm distribution has finally surpassed bullseye for reproducibility: 96.1% vs. 96.0%, despite having over 3500 more packages in the distribution.
Roland Clobus posted his latest update of the status of reproducible Debian ISO images noting that all major desktops build reproducibly with bullseye, bookworm and sid, with the caveat that when non-free firmware is activated, some non-reproducible files are generated .
23 reviews of Debian packages were added, 24 were updated and 20 were removed this month adding to our knowledge about identified issues. A new issue was added and identified by Chris Lamb [], and the timestamps_embedded_in_manpages_by_node_marked_man issue has been marked as resolved [].
Lastly, FC Stegerman reported two issues on Google s own issue tracker: one related to a non-deterministic Dependency Info Block [] and another about a virtual entry added by the signflinger tool causing unexpected differences between signed and unsigned APKs [].
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats.
This month, Chris Lamb released versions 235 and 236; Mattia Rizzolo later released version 237.
Contributions include:
Chris Lamb:
Fix compatibility with PyPDF2 (re. issue #331) [][][].
Fix compatibility with ImageMagick version 7.1 [].
Require at least version 23.1.0 to run the Black source code tests [].
Update debian/tests/control after merging changes from others [].
Don t write test data during a test [].
Update copyright years [].
Merged a large number of changes from others.
Akihiro Suda edited the .gitlab-ci.yml configuration file to ensure that versioned tags are pushed to the container registry [].
Daniel Kahn Gillmor provided a way to migrate from PyPDF2 to pypdf (#1029741).
Efraim Flashner updated the tool metadata for isoinfo on GNU Guix [].
FC Stegerman added support for Android resources.arsc files [], improved a number of file-matching regular expressions [][] and added support for Android dexdump []; they also fixed a test failure (#1031433) caused by Debian s black package having been updated to a newer version.
updated the autopkgtest configuration to only install aapt and dexdump on architectures where they are available [], making sure that the latest diffoscope release is in a good fit for the upcoming Debian bookworm freeze.
reprotestReprotest version 0.7.23 was uploaded to both PyPI and Debian unstable, including the following changes:
Holger Levsen improved a lot of documentation [][][], tidied the documentation as well [][], and experimented with a new --random-locale flag [].
Vagrant Cascadian adjusted reprotest to no longer randomise the build locale and use a UTF-8 supported locale instead [ ] (re. #925879, #1004950), and to also support passing --vary=locales.locale=LOCALE to specify the locale to vary [].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, the following changes were made by Holger Levsen:
Add three new OSUOSL nodes [][][] and decommission the osuosl174 node [].
Change the order of listed Debian architectures to show the 64-bit ones first [].
Reduce the frequency that the Debian package sets and dd-list HTML pages update [].
Sort Tested suite consistently (and Debian unstable first) [].
Update the Jenkins shell monitor script to only query disk statistics every 230min [] and improve the documentation [][].
Other development work
disorderfs version 0.5.11-3 was uploaded by Holger Levsen, fixing a number of issues with the manual page [][][].
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
If you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
This is the second part of how I build a read-only root setup for my router. You might want to read part 1 first, which covers the initial boot and general overview of how I tie the pieces together. This post will describe how I build the squashfs image that forms the main filesystem.
Most of the build is driven from a script, make-router, which I ll dissect below. It s highly tailored to my needs, and this is a fairly lengthy post, but hopefully the steps I describe prove useful to anyone trying to do something similar.
Breakdown of make-router
#!/bin/bash# Either rb3011 (arm) or rb5009 (arm64)#HOSTNAME="rb3011"HOSTNAME="rb5009"if["x$ HOSTNAME"=="xrb3011"];then
ARCH=armhf
elif["x$ HOSTNAME"=="xrb5009"];then
ARCH=arm64
else
echo"Unknown host: $ HOSTNAME"exit 1
fi
It s a bash script, and I allow building for either my RB3011 or RB5009, which means a different architecture (32 vs 64 bit). I run this script on my Pi 4 which means I don t have to mess about with QemuUserEmulation.
BASE_DIR=$(dirname$0)IMAGE_FILE=$(mktemp--tmpdir router.$ ARCH.XXXXXXXXXX.img)MOUNT_POINT=$(mktemp-p /mnt -d router.$ ARCH.XXXXXXXXXX)# Build and mount an ext4 image file to put the root file system indd if=/dev/zero bs=1 count=0 seek=1G of=$ IMAGE_FILE
mkfs -t ext4 $ IMAGE_FILE
mount -o loop $ IMAGE_FILE$ MOUNT_POINT
I build the image in a loopback ext4 file on tmpfs (my Pi4 is the 8G model), which makes things a bit faster.
# Add dpkg excludesmkdir-p$ MOUNT_POINT/etc/dpkg/dpkg.cfg.d/
cat<<EOF > $ MOUNT_POINT/etc/dpkg/dpkg.cfg.d/path-excludes
# Exclude docs
path-exclude=/usr/share/doc/*
# Only locale we want is English
path-exclude=/usr/share/locale/*
path-include=/usr/share/locale/en*/*
path-include=/usr/share/locale/locale.alias
# No man pages
path-exclude=/usr/share/man/*
EOF
Create a dpkg excludes config to drop docs, man pages and most locales before we even start the bootstrap.
Actually do the debootstrap step, including a bunch of extra packages that we want.
# Install mqtt-arpcp$ BASE_DIR/debs/mqtt-arp_1_$ ARCH.deb $ MOUNT_POINT/tmp
chroot$ MOUNT_POINT dpkg -i /tmp/mqtt-arp_1_$ ARCH.deb
rm$ MOUNT_POINT/tmp/mqtt-arp_1_$ ARCH.deb
# Frob the mqtt-arp config so it starts after mosquittosed-i-e's/After=.*/After=mosquitto.service/'$ MOUNT_POINT/lib/systemd/system/mqtt-arp.service
I haven t uploaded mqtt-arp to Debian, so I install a locally built package, and ensure it starts after mosquitto (the MQTT broker), given they re running on the same host.
# Frob watchdog so it starts earlier than multi-usersed-i-e's/After=.*/After=basic.target/'$ MOUNT_POINT/lib/systemd/system/watchdog.service
# Make sure the watchdog is poking the device filesed-i-e's/^#watchdog-device/watchdog-device/'$ MOUNT_POINT/etc/watchdog.conf
watchdog timeouts were particularly an issue on the RB3011, where the default timeout didn t give enough time to reach multiuser mode before it would reset the router. Not helpful, so alter the config to start it earlier (and make sure it s configured to actually kick the device file).
# Clean up docs + localesrm-r$ MOUNT_POINT/usr/share/doc/*rm-r$ MOUNT_POINT/usr/share/man/*for dir in$ MOUNT_POINT/usr/share/locale/*/;do
if["$ dir"!="$ MOUNT_POINT/usr/share/locale/en/"];then
rm-r$ dirfi
done
Clean up any docs etc that ended up installed.
# Set root password to rootecho"root:root"chroot$ MOUNT_POINT chpasswd
The only login method is ssh key to the root account though I suppose this allows for someone to execute a privilege escalation from a daemon user so I should probably randomise this. Does need to be known though so it s possible to login via the serial console for debugging.
There are config files that are easier to replace wholesale, some of which are specific to the hardware (e.g. related to network interfaces). See below for some more details.
# Build symlinks into flash for boot / modulesln-s /mnt/flash/lib/modules $ MOUNT_POINT/lib/modules
rmdir$ MOUNT_POINT/boot
ln-s /mnt/flash/boot $ MOUNT_POINT/boot
The kernel + its modules live outside the squashfs image, on the USB flash drive that the image lives on. That makes for easier kernel upgrades.
# Put our git revision into os-releaseecho-n"GIT_VERSION=">>$ MOUNT_POINT/etc/os-release
(cd$ BASE_DIR; git describe --tags)>>$ MOUNT_POINT/etc/os-release
Always helpful to be able to check the image itself for what it was built from.
# Add some stuff to root's .bashrccat<<EOF >> $ MOUNT_POINT/root/.bashrc
alias ls='ls -F --color=auto'
eval "\$(dircolors)"
case "\$TERM" in
xterm* rxvt*)
PS1="\\[\\e]0;\\u@\\h: \\w\a\\]\$PS1"
;;
*)
;;
esac
EOF
Just some niceties for when I do end up logging in.
# Save the installed package list offchroot$ MOUNT_POINT dpkg --get-selections> /tmp/wip-installed-packages
Save off the installed package list. This was particularly useful when trying to replicate the existing router setup and making sure I had all the important packages installed. It doesn t really serve a purpose now.
In terms of the config files I copy into /etc, shared across both routers are the following:
Breakdown of shared config
This is the second in a series of blog posts introducing Carthage,
an Infrastructure as Code framework I ve been working on the last four
years. In this post we ll talk about how we use Carthage to build the
Carthage container images. We absolutely could have just used a
Containerfile to do this; in fact I recently removed a hybrid solution that produced an artifact
and then used a Containerfile to turn it into an OCI image. The biggest
reason we don t use a Containerfile is that we want to be able to reuse
the same infrastructure (installed software and configuration) across
multiple environments. For example CarthageServerRole, a
reusable Carthage component that install Carthage itself is used in
several places:
on raw hardware when we re using Carthage to drive a hypervisor
As part of image building pipelines to build AMIs for Amazon Web
Services
Installed onto AWS instances built from the Debian AMI where we
cannot use custom AMIs
Installed onto KVM VMs
As part of building the Carthage container images
So the biggest thing Carthage gives us is uniformity in how we set up
infrastructure. We ve found a number of disadvantages of Containerfiles
as well:
Containerfiles mix the disadvantages of imperative and
declarative formats. Like a declarative format they have no explicit
control logic. It seems like that would be good for introspecting and
reasoning about Containers. But all you get is the base image and a set
of commands to build a container. For reasoning about common things like
whether a container has a particular vulnerability or can be distributed
under a particular license, that s not very useful. So we don t get much
valuable introspection out of the declarative aspects, and all too often
we see Containerfiles generated by Makefiles or other multi-level
build-systems to get more logic or control flow.
Containerfiles have limited facility for doing things outside the
container. The disadvantage of this is that you end up installing all
the software you need to build the container into the container itself
(or having a multi-level build system). But for example if I want to use
Ansible to configure a container, the easiest way to do that is to
actually install Ansible into the container itself, even though Ansible
has a large dependency chain most of which we won t need in the
container. Yes, Ansible does have a number of connection methods
including one for Buildah, but by the point you re using that, you re
already using a multi-level build system and aren t really just using a
Containerfile.
Okay, so since we re not going to just use a Containerfile, what do
we do instead? We produce a CarthageLayout.
A CarthageLayout is an object in the Carthage modeling
language. The modeling language looks a lot like Python in fact it s
even implemented using Python metaclasses and uses the Python parser.
However, there are some key semantic differences and it may help to
think of the modeling language as its own thing. Carthage layouts are
typically contained in Carthage plugins. For example, the oci_images plugin is our focus today. Most of the
work in that plugin is in layout.py, and the layout begins here:
class layout(CarthageLayout): add_provider(ConfigLayout) add_provider(carthage.ansible.ansible_log, str(_dir/"ansible.log"))
The add_provider calls are special, and we ll discuss them
in a future post. For now, think of them as assignments in a more
complex namespace than simple identifiers. But the heart of this layout
is the CarthageImage class:
Most of the work of our image is done by inheritance. We inherit from
the CarthageServerRole from the carthage_base plugin collection. A role is a
reusable set of infrastructure that can be attached directly to a MachineModel.
By inheriting from this role, we request the installation of the
Carthage software. The role also supports copying in various
dependencies; for example when Carthage is used to manage a cluster of
machines, the layout corresponding to the cluster can automatically be
copied to all nodes in the cluster. We do not need this feature to build
the container image. The CarthageImage class sets its base
image. Currently we are using our own base Debian image that we build
with debootstrap and then import as a container image. In
the fairly near future, we ll change that to:
base_image = debian:bookworm
That will simply use the Debian image from Dockerhub. We are building
our own base image for historical reasons and need to confirm that
everything works before switching over. By setting
oci_image_tag we specify where in the local images the
resulting image will be stored. We also specify that this image boots
systemd. We actually do want to do a bit of work on top of
CarthageServerRole specific to the container image. To do that
we use a Carthage feature called a Customization. There are
various types of customization. For example
MachineCustomization runs a set of tasks on a Machine that is
booted and on the network. When building images, the most common type of
customization is a FilesystemCustomization. For these, we have
access to the filesystem, and we have some way of running a command in
the context of the filesystem. We don t boot the filesystem as a machine
unless we need to. (We might if the filesystem is a kvm VM or AWS
instance for example). Carthage collects all the customizations in a
role or image model. In the case of container image classes like
PodmanImageModel, each customization is applied as an
individual layer in the resulting container image.
Roles and customizations are both reusable infrastructure. Roles
typically contain customizations. Roles operate at the modeling layer;
you might introspect a machine s model or an image s model to see what
functionality (roles) it provides. In contrast, customizations operate
at the implementation layer. They do specific things like move files
around, apply Ansible roles or similar.
Let s take a look at the customization applied for the Carthage
container image (full code):
class customize_for_oci(FilesystemCustomization):@setup_task("Remove Software")asyncdef remove_software(self):awaitself.run_command("apt", "-y", "purge","exim4-base", )@setup_task("Install service")asyncdef install_service(self):# installs and activates a systemd unit
Then to pull it all together, we simply run the layout:
Welcome to the first report for 2023 from the Reproducible Builds project!
In these reports we try and outline the most important things that we have been up to over the past month, as well as the most important things in/around the community. As a quick recap, the motivation behind the reproducible builds effort is to ensure no malicious flaws can be deliberately introduced during compilation and distribution of the software that we run on our devices. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
News
In a curious turn of events, GitHub first announced this month that the checksums of various Git archives may be subject to change, specifically that because:
the default compression for Git archives has recently changed. As result, archives downloaded from GitHub may have different checksums even though the contents are completely unchanged.
This change (which was brought up on our mailing list last October) would have had quite wide-ranging implications for anyone wishing to validate and verify downloaded archives using cryptographic signatures. However, GitHub reversed this decision, updating their original announcement with a message that We are reverting this change for now. More details to follow. It appears that this was informed in part by an in-depth discussion in the GitHub Community issue tracker.
The Bundesamt f r Sicherheit in der Informationstechnik (BSI) (trans: The Federal Office for Information Security ) is the agency in charge of managing computer and communication security for the German federal government. They recently produced a report that touches on attacks on software supply-chains (Supply-Chain-Angriff). (German PDF)
Contributor Seb35 updated our website to fix broken links to Tails Git repository [][], and Holger updated a large number of pages around our recent summit in Venice [][][][].
Noak J nsson has written an interesting paper entitled The State of Software Diversity in the Software Supply Chain of Ethereum Clients. As the paper outlines:
In this report, the software supply chains of the most popular Ethereum clients are cataloged and analyzed. The dependency graphs of Ethereum clients developed in Go, Rust, and Java, are studied. These client are Geth, Prysm, OpenEthereum, Lighthouse, Besu, and Teku. To do so, their dependency graphs are transformed into a unified format. Quantitative metrics are used to depict the software supply chain of the blockchain. The results show a clear difference in the size of the software supply chain required for the execution layer and consensus layer of Ethereum.
F-Droid & Android
There was a very large number of changes in the F-Droid and wider Android ecosystem this month:
On January 15th, a blog post entitled Towards a reproducible F-Droid was published on the F-Droid website, outlining the reasons why F-Droid signs published APKs with its own keys and how reproducible builds allow using upstream developers keys instead. In particular:
GitLab user Parwor discovered that the number of CPU cores can affect the reproducibility of .dex files. []
FC Stegerman also announced the 0.2.0 and 0.2.1 releases of reproducible-apk-tools, a suite of tools to help make .apk files reproducible. Several new subcommands and scripts were added, and a number of bugs were fixed as well [][]. They also updated the F-Droid website to improve the reproducibility-related documentation. [][]
A number of bugs related to reproducibility were discovered in Android itself. Firstly, the non-deterministic order of .zip entries in .apk files [] and then newline differences between building on Windows versus Linux that can make builds not reproducible as well. [] (Note that these links may require a Google account to view.)
Debian
As mentioned in last month s report, Vagrant Cascadian has been organising a series of online sprints in order to clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads). During January, a sprint took place on the 10th, resulting in the following uploads:
During this sprint, Holger Levsen filed Debian bug #1028615 to request that the tracker.debian.org service display results of reproducible rebuilds, not just reproducible CI results.
Elsewhere in Debian, strip-nondeterminism is our tool to remove specific non-deterministic results from a completed build. This month, version 1.13.1-1 was uploaded to Debian unstable by Holger Levsen, including a fix by FC Stegerman (obfusk) to update a regular expression for the latest version of file(1) []. (#1028892)
Lastly, 65 reviews of Debian packages were added, 21 were updated and 35 were removed this month adding to our knowledge about identified issues.
Finally, an existing tool called rpmreproduce was (re-)discovered this month, which claims that given a buildinfo file from a RPM package, [it can] generate instructions for attempting to reproduce the binary packages built from the associated source and build information.
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 231, 232, 233 and 234 to Debian:
No need for from __future__ import print_function import anymore. []
Comment and tidy the extras_require.json handling. []
Split inline Python code to generate test Recommends into a separate Python script. []
Update debian/tests/control after merging support for PyPDF support. []
Correctly catch segfaulting cd-iccdump binary. []
Drop some old debugging code. []
Allow ICC tests to (temporarily) fail. []
In addition, FC Stegerman (obfusk) made a number of changes, including:
Updating the test_text_proper_indentation test to support the latest version(s) of file(1). []
Use an extras_require.json file to store some build/release metadata, instead of accessing the internet. []
Updating an APK-related file(1) regular expression. []
Lastly, Sam James added support for PyPDF version 3 [] and Vagrant Cascadian updated a handful of tool references for GNU Guix. [][]
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, we wrote a large number of such patches, including:
Several patches for file(1) (which is used by reproducible builds tools like diffoscope and strip-nondeterminism) that improve detection of various file formats are now included in the Debian packaging. []
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In January, the following changes were made by Holger Levsen:
Node changes:
Add three new nodes hosted at the Oregon State University Open Source Lab including integrating them into the DNS, maintenance and monitoring systems. [][][][][]
Debian-related changes:
Only keep diffoscope s HTML output (ie. no .json or .txt) for LTS suites and older in order to save diskspace on the Jenkins host. []
Re-create pbuilder base less frequently for the stretch, bookworm and experimental suites. []
OpenWrt-related changes:
Add gcc-multilib to OPENWRT_HOST_PACKAGES and install it on the nodes that need it. []
Detect more problems in the health check when failing to build OpenWrt. []
Misc changes:
Update the chroot-run script to correctly manage /dev and /dev/pts. [][][]
Update the Jenkins shell monitor script to collect disk stats less frequently [] and to include various directory stats. [][]
Update the real year in the configuration in order to be able to detect whether a node is running in the future or not. []
Bump copyright years in the default page footer. []
In addition, Christian Marangi submitted a patch to build OpenWrt packages with the V=s flag to enable debugging. []
If you are interested in contributing to the Reproducible Builds project, please visit the Contribute page on our website. You can get in touch with us via:
Linux desktop systems
have
standardized how programs present themselves to the desktop
system. If a package include a .desktop file in
/usr/share/applications/, Gnome, KDE, LXDE, Xfce and the other desktop
environments will pick up the file and use its content to generate the
menu of available programs in the system. A lesser known fact is that
a package can also explain to the desktop system how to recognize the
files created by the program in question, and use it to open these
files on request, for example via a GUI file browser.
A while back I ran into a package that did not tell the desktop
system how to recognize its files and was not used to open its files
in the file browser and fixed it. In the process I wrote a simple
debian/tests/ script to ensure the setup keep working. It might be
useful for other packages too, to ensure any future version of the
package keep handling its own files.
For this to work the file format need a useful MIME type that can
be used to identify the format. If the file format do not yet have a
MIME type, it should define one and preferably also
register
it with IANA to ensure the MIME type string is reserved.
The script uses the xdg-mime program from xdg-utils to
query the database of standardized package information and ensure it
return sensible values. It also need the location of an example file
for xdg-mime to guess the format of.
#!/bin/sh
#
# Author: Petter Reinholdtsen
# License: GPL v2 or later at your choice.
#
# Validate the MIME setup, making sure motor types have
# application/vnd.openmotor+yaml associated with them and is connected
# to the openmotor desktop file.
retval=0
mimetype="application/vnd.openmotor+yaml"
testfile="test/data/real/o3100/motor.ric"
mydesktopfile="openmotor.desktop"
filemime="$(xdg-mime query filetype "$testfile")"
if [ "$mimetype" != "$filemime" ] ; then
retval=1
echo "error: xdg-mime claim motor file MIME type is $filemine, not $mimetype"
else
echo "success: xdg-mime report correct mime type $mimetype for motor file"
fi
desktop=$(xdg-mime query default "$mimetype")
if [ "$mydesktopfile" != "$desktop" ]; then
retval=1
echo "error: xdg-mime claim motor file should be handled by $desktop, not $mydesktopfile"
else
echo "success: xdg-mime agree motor file should be handled by $mydesktopfile"
fi
exit $retval
It is a simple way to ensure your users are not very surprised when
they try to open one of your file formats in their file browser.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
We plan to spend three days continuing to the grow of the Reproducible Builds effort. As in previous events, the exact content of the meeting will be shaped by the participants. And, as mentioned in Holger Levsen s post to our mailing list, the dates have been booked and confirmed with the venue, so if you are considering attending, please reserve these dates in your calendar today.
R my Gr nblatt, an associate professor in the T l com Sud-Paris engineering school wrote up his pain points of using Nix and NixOS. Although some of the points do not touch on reproducible builds, R my touches on problems he has encountered with the different kinds of reproducibility that these distributions appear to promise including configuration files affecting the behaviour of systems, the fragility of upstream sources as well as the conventional idea of binary reproducibility.
Morten Linderud reported that he is quietly optimistic that if Go programming language resolves all of its issues with reproducible builds (tracking issue) then the Go binaries distributed from Google and by Arch Linux may be bit-for-bit identical. It s just a bit early to sorta figure out what roadblocks there are. [But] Go bootstraps itself every build, so in theory I think it should be possible.
On December 15th, Holger Levsen published an in-depth interview he performed with David A. Wheeler on supply-chain security and reproducible builds, but it also touches on the biggest challenges in computing as well.
This is part of a larger series of posts featuring the projects, companies and individuals who support the Reproducible Builds project. Other instalments include an article featuring the Civil Infrastructure Platform project and followed this up with a post about the Ford Foundation as well as a recent ones about ARDC, the Google Open Source Security Team (GOSST), Jan Nieuwenhuizen on Bootstrappable Builds, GNU Mes and GNU Guix and Hans-Christoph Steiner of the F-Droid project.
A number of changes were made to the Reproducible Builds website and documentation this month, including FC Stegerman adding an F-Droid/apksigcopier example to our embedded signatures page [], Holger Levsen making a large number of changes related to the 2022 summit in Venice as well as 2023 s summit in Hamburg [][][][] and Simon Butler updated our publications page [][].
On our mailing list this month, James Addison asked a question about whether there has been any effort to trace the files used by a build system in order to identify the corresponding build-dependency packages. [] In addition, Bernhard M. Wiedemann then posed a thought-provoking question asking How to talk to skeptics? , which was occasioned by a colleague who had published a blog post in May 2021 skeptical of reproducible builds. The thread generated a number of replies.
Android news
obfusk (FC Stegerman) performed a thought-provoking review of tools designed to determine the difference between two different .apk files shipped by a number of free-software instant messenger applications.
These scripts are often necessary in the Android/APK ecosystem due to these files containing embedded signatures so the conventional bit-for-bit comparison cannot be used. After detailing a litany of issues with these tools, they come to the conclusion that:
It s quite possible these messengers actually have reproducible builds, but the verification scripts they use don t actually allow us to verify whether they do.
This reflects the consensus view within the Reproducible Builds project: pursuing a situation in language or package ecosystems where binaries are bit-for-bit identical (over requiring a bespoke ecosystem-specific tool) is not a luxury demanded by purist engineers, but rather the only practical way to demonstrate reproducibility. obfusk also announced the first release of their own set of tools on our mailing list.
Related to this, obfusk also posted to an issue filed against Mastodon regarding the difficulties of creating bit-by-bit identical APKs, especially with respect to copying v2/v3 APK signatures created by different tools; they also reported that some APK ordering differences were not caused by building on macOS after all, but by using Android Studio [] and that F-Droid added 16 more apps published with Reproducible Builds in December.
Debian
As mentioned in last months report, Vagrant Cascadian has been organising a series of online sprints in order to clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads).
During December, meetings were held on the 1st, 8th, 15th, 22nd and 29th, resulting in a large number of uploads and bugs being addressed:
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, we wrote a large number of such patches, including:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In October, the following changes were made by Holger Levsen:
The osuosl167 machine is no longer a openqa-worker node anymore. [][]
Detect problems with APT repository signatures [] and update a repository signing key [].
Only install the foot-terminfo package on Debian systems. []
In addition, Mattia Rizzolo added support for the version of diffoscope in Debian stretch which doesn t support the --timeout flag. [][]
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 228, 229 and 230 to Debian:
Fix compatibility with file(1) version 5.43, with thanks to Christoph Biedl. []
Skip the test_html.py::test_diff test if html2text is not installed. (#1026034)
Update copyright years. []
In addition, Jelle van der Waa added support for Berkeley DB version 6. []
Orthogonal to this, Holger Levsen bumped the Debian Standards-Version on all of our packages, including diffoscope [], strip-nondeterminism [], disorderfs [] and reprotest [].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. You can get in touch with us via:
Sweep of the Heart is the sixth book of the sci-fi urban fantasy,
kitchen-sink-worldbuilding Innkeeper series by husband and wife writing
pair Ilona Andrews, assuming one counts the novella
Sweep with Me as a full entry (which I
do). It's a direct sequel to One Fell
Sweep, but also references the events of Sweep of the Blade and Sweep with Me enough to spoil them.
Needless to say, don't start here.
As always with this series, the book was originally published as a serial
on Ilona Andrews's blog. I
prefer to read my novels as novels, so I wait until the entries are
collected and published, but you can read it on-line for free if you want.
Sean and Dina's old friend Wilmos has been kidnapped by an enemy who looks
familiar from One Fell Sweep. To get him back, they need to get to
a world that is notoriously inaccessible. One player in galactic politics
may be able to offer a portal, but it will come as a price.
That price? Host a reality TV show. Specifically, a sci-fi version of
The Bachelor, with aliens. And the bachelor is the ruler of a
galactic empire, whose personal safety is now Dina's responsibility.
There is a hand-waving explanation for why the Seven Star Dominion does
spouse selection for their rulers this way, but let's be honest: it's a
fairly transparent excuse to write a season of The Bachelor with
strange aliens, political intrigue, inn-generated special effects and
wallpaper-worthy backdrops, ulterior motives, and attempted murder. Oh,
and competence porn, as Dina once again demonstrates just how good she's
become at being an innkeeper.
I'm not much of a reality TV fan, have never watched The Bachelor,
and still thoroughly enjoyed this. It helps that the story is more about
political intrigue than it is about superficial attraction or personal
infighting, and the emperor at the center of the drama is calm,
thoughtful, and juggling a large number of tricky problems (which Dina,
somewhat improbably, becomes privy to). The contestants range from
careful diplomats with hidden political goals to eye candy with the
subtlety of a two by four, the latter sponsored by sentient murderous
trees, so there's a delightful variety of tone and a ton of narrative
momentum. A few of the twists and turns were obvious, but some of the
cliches are less cliched than they initially look.
This series always leans towards "play with every toy in the toy box at
once!" rather than subtle and realistic. This entry is no exception, but
the mish-mash of science fiction tropes with nigh-unlimited fantasy power
is, as usual, done with so much verve and sheer creative joy that I can't
help but love it.
We do finally learn Caldenia's past, and... I kind of wish we hadn't? Or
at least that her past had been a bit more complicated. I will avoid
spoiling it by saying too much, but I thought it was an oddly flat and
overdone trope that made Caldenia substantially less interesting than she
was before this revelation.
That was one mild disappointment. The other is that the opening of
Sweep of the Heart teases some development of the overall series
plot, but that remains mostly a tease. Wilmos's kidnapping and any
relevance to deeper innkeeper problems is, at least in this entry, merely a
framing story for the reality TV show that constitutes the bulk of the
novel. There are a few small revelations in the conclusion, but only the
type that raise more questions. Hopefully we'll get more series plot
development in the next book, but even if we don't, I'm happily along for
the ride.
If you like this series, this is more of the thing you already like. If
you haven't read it yet, I highly recommend it (start with
Clean Sweep). It's not great
literature, and most of the trappings will be familiar from a dozen other
novels and TV shows, but it's unabashed fun with loads of competence porn
and a wild internal logic that grows on you over time. Also, it has one
of the most emotionally satisfying sentient buildings in SF.
There will, presumably, be more entries in the series, but they have not
yet been announced.
Rating: 8 out of 10
Welcome to yet another report from the Reproducible Builds project, this time for November 2022. In all of these reports (which we have been publishing regularly since May 2015) we attempt to outline the most important things that we have been up to over the past month. As always, if you interested in contributing to the project, please visit our Contribute page on our website.
Reproducible Builds Summit 2022
Following-up from last month s report about our recent summit in Venice, Italy, a comprehensive report from the meeting has not been finalised yet watch this space!
As a very small preview, however, we can link to several issues that were filed about the website during the summit (#38, #39, #40, #41, #42, #43, etc.) and collectively learned about Software Bill of Materials (SBOM) s and how .buildinfo files can be seen/used as SBOMs. And, no less importantly, the Reproducible Builds t-shirt design has been updated
Reproducible Builds at European Cyber Week 2022
During the European Cyber Week 2022, a Capture The Flag (CTF) cybersecurity challenge was created by Fr d ric Pierret on the subject of Reproducible Builds. The challenge consisted in a pedagogical sense based on how to make a software release reproducible. To progress through the challenge issues that affect the reproducibility of build (such as build path, timestamps, file ordering, etc.) were to be fixed in steps in order to get the final flag in order to win the challenge.
At the end of the competition, five people succeeded in solving the challenge, all of whom were awarded with a shirt. Fr d ric Pierret intends to create similar challenge in the form of a how to in the Reproducible Builds documentation, but two of the 2022 winners are shown here:
[ ] industry application of R-Bs appears limited, and we seek to understand whether awareness is low or if significant technical and business reasons prevent wider adoption.
This is achieved through interviews with software practitioners and business managers, and touches on both the business and technical reasons supporting the adoption (or not) of Reproducible Builds. The article also begins with an excellent explanation and literature review, and even introduces a new helpful analogy for reproducible builds:
[Users are] able to perform a bitwise comparison of the two binaries to verify that they are identical and that the distributed binary is indeed built from the source code in the way the provider claims. Applied in this manner, R-Bs function as a canary, a mechanism that indicates when something might be wrong, and offer an improvement in security over running unverified binaries on computer systems.
The full paper is available to download on an open access basis.
Elsewhere in academia, Beatriz Michelson Reichert and Rafael R. Obelheiro have published a paper proposing a systematic threat model for a generic software development pipeline identifying possible mitigations for each threat (PDF). Under the Tampering rubric of their paper, various attacks against Continuous Integration (CI) processes:
An attacker may insert a backdoor into a CI or build tool and thus introduce vulnerabilities into the software (resulting in an improper build). To avoid this threat, it is the developer s responsibility to take due care when making use of third-party build tools. Tampered compilers can be mitigated using diversity, as in the diverse double compiling (DDC) technique. Reproducible builds, a recent research topic, can also provide mitigation for this problem. (PDF)
Misc news
A change was proposed for the Go programming language to enable reproducible builds when Link Time Optimisation (LTO) is enabled. As mentioned in the changelog, Morten Linderud s patch fixes two issues when the linker used in conjunction with the -flto option: the first involves solving an issue related to seeded random numbers; and the second involved the binary embedding the current working directory in compressed sections of the LTO object. Both of these issues made the build unreproducible.
Our monthly IRC meeting was held on November 29th 2022. Our next meeting will be on January 31st 2023; we ll skip the meeting in December due to the proximity to Christmas, etc.
Vagrant Cascadian posed an interesting question regarding the difference between test builds vs rebuilds (or verification rebuilds ). As Vagrant poses in their message, they re both useful for slightly different purposes, and it might be good to clarify the distinction [ ].
Debian & other Linux distributions
Over 50 reviews of Debian packages were added this month, another 48 were updated and almost 30 were removed, all of which adds to our knowledge about identified issues. Two new issue types were added as well. [][].
Vagrant Cascadian announced on our mailing list another online sprint to help clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads). The first such sprint took place on September 22nd, but others were held on October 6th and October 20th. There were two additional sprints that occurred in November, however, which resulted in the following progress:
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 226 and 227 to Debian:
Support both python3-progressbar and python3-progressbar2, two modules providing the progressbar Python module. []
Don t run Python decompiling tests on Python bytecode that file(1) cannot detect yet and Python 3.11 cannot unmarshal. (#1024335)
Don t attempt to attach text-only differences notice if there are no differences to begin with. (#1024171)
Make sure we recommend apksigcopier. []
Tidy generation of os_list. []
Make the code clearer around generating the Debian substvars . []
Use our assert_diff helper in test_lzip.py. []
Drop other copyright notices from lzip.py and test_lzip.py. []
In addition to this, Christopher Baines added lzip support [], and FC Stegerman added an optimisation whereby we don t run apktool if no differences are detected before the signing block [].
A significant number of changes were made to the Reproducible Builds website and documentation this month, including Chris Lamb ensuring the openEuler logo is correctly visible with a white background [], FC Stegerman de-duplicated by email address to avoid listing some contributors twice [], Herv Boutemy added Apache Maven to the list of affiliated projects [] and boyska updated our Contribute page to remark that the Reproducible Builds presence on salsa.debian.org is not just the Git repository but is also for creating issues [][]. In addition to all this, however, Holger Levsen made the following changes:
Add a number of existing publications [][] and update metadata for some existing publications as well [].
Add the Warpforge build tool as a participating project of the summit. []
Clarify in the footer that we welcome patches to the website repository. []
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In October, the following changes were made by Holger Levsen:
Improve the generation of meta package sets (used in grouping packages for reporting/statistical purposes) to treat Debian bookworm as equivalent to Debian unstable in this specific case []
and to parse the list of packages used in the Debian cloud images [][][].
Temporarily allow Frederic to ssh(1) into our snapshot server as the jenkins user. []
Keep some reproducible jobs Jenkins logs much longer [] (later reverted).
Improve the node health checks to detect failures to update the Debian cloud image package set [][] and to improve prioritisation of some kernel warnings [].
Always echo any IRC output to Jenkins output as well. []
Deal gracefully with problems related to processing the cloud image package set. []
Finally, Roland Clobus continued his work on testing Live Debian images, including adding support for specifying the origin of the Debian installer [] and to warn when the image has unmet dependencies in the package list (e.g. due to a transition) [].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. You can get in touch with us via:
A first update to the recently-released package spdl is now om CRAN. The key focus of spdl is a offering the same interface from both R and C++ for logging by relying on spdlog via my RcppSpdlog package.
This release exposes simple helpers fmt() (to format text according to the included fmt library) and cat() which formats and prints.
The very short NEWS entry for this release follows.
Welcome to the Reproducible Builds report for October 2022! In these reports we attempt to outline the most important things that we have been up to over the past month.
As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Our in-person summit this year was held in the past few days in Venice, Italy. Activity and news from the summit will therefore be covered in next month s report!
A new article related to reproducible builds was recently published in the 2023 IEEE Symposium on Security and Privacy. Titled Taxonomy of Attacks on Open-Source Software Supply Chains and authored by Piergiorgio Ladisa, Henrik Plate, Matias Martinez and Olivier Barais, their paper:
[ ] proposes a general taxonomy for attacks on opensource supply chains, independent of specific programming languages or ecosystems, and covering all supply chain stages from code contributions to package distribution.
Taking the form of an attack tree, the paper covers 107 unique vectors linked to 94 real world supply-chain incidents which is then mapped to 33 mitigating safeguards including, of course, reproducible builds:
Reproducible Builds received a very high utility rating (5) from 10 participants (58.8%), but also a high-cost rating (4 or 5) from 12 (70.6%). One expert commented that a reproducible build like used by Solarwinds now, is a good measure against tampering with a single build system and another claimed this is going to be the single, biggest barrier .
[ ] illustrate a concerning new reality for the software industry and illuminates the increasingly sophisticated threats made by outside nation-states to the supply chains and infrastructure on which we all rely.
The 12-month anniversary of the 2020 Solarwinds attack (which SolarWinds Worldwide LLC itself calls the SUNBURST attack) was, of course, the likely impetus for publication.
Whilst collaborating on making the Cyrus IMAP server reproducible, Ellie Timoney asked why the Reproducible Builds testing framework uses two remarkably distinctive build paths when attempting to flush out builds that vary on the absolute system path in which they were built. In the case of the Cyrus IMAP server, these happened to be:
Arch Linux contributor kpcyrd wrote to our list this month with the news that multiple people in Arch Linux noticed the output of our git archive command doesn t match the tarball served by GitHub anymore. In his post, kpcyrd narrows the change to a specific commit in Git. []
Akihiro Suda wrote to a share a new tool called repro-get. According to Akihiro s post, repro-get is a tool to install a specific snapshot of apt/dnf/apk/pacman packages using SHA256SUMS files . This is needed in order to install specific (or pinned ) dependencies needed to validate a build.
Finally, Janneke Nieuwenhuizen announced the release of GNU Mes 0.24.1, which represents 23 commits over five months by four people. GNU Mes is a Scheme interpreter and C compiler for bootstrapping the GNU System. []
The Reproducible Builds project is delighted to welcome openEuler to the Involved projects page []. openEuler is Linux distribution developed by Huawei, a counterpart to it s more commercially-oriented EulerOS.
Debian
Colin Watson wrote about his experience towards making the databases generated by the man-db UNIX manual page indexing tool:
One of the people working on [reproducible builds] noticed that man-db s database files were an obstacle to [reproducibility]: in particular, the exact contents of the database seemed to depend on the order in which files were scanned when building it. The reporter proposed solving this by processing files in sorted order, but I wasn t keen on that approach: firstly because it would mean we could no longer process files in an order that makes it more efficient to read them all from disk (still valuable on rotational disks), but mostly because the differences seemed to point to other bugs.
Colin goes on to describe his approach to solving the problem, including fixing various fits of internal caching, and he ends his post with None of this is particularly glamorous work, but it paid off .
Vagrant Cascadian announced on our mailing list another online sprint to help clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads). The first such sprint took place on September 22nd, but another was held on October 6th, and another small one on October 20th. This resulted in the following progress:
41 reviews of Debian packages were added, 62 were updated and 12 were removed this month adding to our knowledge about identified issues. A number of issue types were updated too. [1][]
Lastly, Luca Boccassi submitted a patch to debhelper, a set of tools used in the packaging of the majority of Debian packages. The patch addressed an issue in the dh_installsysusers utility so that the postinst post-installation script that debhelper generates the same data regardless of the underlying filesystem ordering.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 224 and 225 to Debian:
Add support for comparing the text content of HTML files using html2text. []
Add support for detecting ordering-only differences in XML files. []
Fix an issue with detecting ordering differences. []
Use the capitalised version of Ordering consistently everywhere in output. []
Add support for displaying font metadata using ttx(1) from the fonttools suite. []
Testsuite improvements:
Temporarily allow the stable-po pipeline to fail in the CI. []
Rename the order1.diff test fixture to json_expected_ordering_diff. []
Tidy the JSON tests. []
Use assert_diff over get_data and an manual assert within the XML tests. []
Drop the ALLOWED_TEST_FILES test; it was mostly just annoying. []
Tidy the tests/test_source.py file. []
Chris Lamb also added a link to diffoscope s OpenBSD packaging on the diffoscope.org homepage [] and Mattia Rizzolo fix an test failure that was occurring under with LLVM 15 [].
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In October, the following changes were made by Holger Levsen:
Run the logparse tool to analyse results on the Debian Edu build logs. []
Install btop(1) on all nodes running Debian. []
Switch Arch Linux from using SHA1 to SHA256. []
When checking Debian debstrap jobs, correctly log the tool usage. []
Cleanup more task-related temporary directory names when testing Debian packages. [][]
Use the cdebootstrap-static binary for the 2nd runs of the cdebootstrap tests. []
Drop a workaround when testing OpenWrt and coreboot as the issue in diffoscope has now been fixed. []
Turn on an rm(1) warning into an info -level message. []
Special case the osuosl168 node for running Debian bookworm already. [][]
Use the new non-free-firmware suite on the o168 node. []
In addition, Mattia Rizzolo made the following changes:
Ensure that 2nd build has a merged /usr. []
Only reconfigure the usrmerge package on Debian bookworm and above. []
Fix bc(1) syntax in the computation of the percentage of unreproducible packages in the dashboard. [][][]
In the index_suite_ pages, order the package status to be the same order of the menu. []
Pass the --distribution parameter to the pbuilder utility. []
Finally, Roland Clobus continued his work on testing Live Debian images. In particular, he extended the maintenance script to warn when workspace directories cannot be deleted. []
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Welcome to the September 2022 report from the Reproducible Builds project! In our reports we try to outline the most important things that we have been up to over the past month. As a quick recap, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries. If you are interested in contributing to the project, please visit our Contribute page on our website.
David A. Wheeler reported to us that the US National Security Agency (NSA), Cybersecurity and Infrastructure Security Agency (CISA) and the Office of the Director of National Intelligence (ODNI) have released a document called Securing the Software Supply Chain: Recommended Practices Guide for Developers (PDF).
As David remarked in his post to our mailing list, it expressly recommends having reproducible builds as part of advanced recommended mitigations . The publication of this document has been accompanied by a press release.
Holger Levsen was made aware of a small Microsoft project called oss-reproducible. Part of, OSSGadget, a larger collection of tools for analyzing open source packages , the purpose of oss-reproducible is to:
analyze open source packages for reproducibility. We start with an existing package (for example, the NPM left-pad package, version 1.3.0), and we try to answer the question, Do the package contents authentically reflect the purported source code?
More details can be found in the README.md file within the code repository.
David A. Wheeler also pointed out that there are some potential upcoming changes to the OpenSSF Best Practices badge for open source software in relation to reproducibility. Whilst the badge programme has three certification levels ( passing , silver and gold ), the gold level includes the criterion that The project MUST have a reproducible build .
David reported that some projects have argued that this reproducibility criterion should be slightly relaxed as outlined in an issue on the best-practices-badge GitHub project. Essentially, though, the claim is that the reproducibility requirement doesn t make sense for projects that do not release built software, and that timestamp differences by themselves don t necessarily indicate malicious changes. Numerous pragmatic problems around excluding timestamps were raised in the discussion of the issue.
Sonatype, a pioneer of software supply chain management , issued a press release month to report that they had found:
[ ] a massive year-over-year increase in cyberattacks aimed at open source project ecosystems. According to early data from Sonatype s 8th annual State of the Software Supply Chain Report, which will be released in full this October, Sonatype has recorded an average 700% jump in repository attacks over the last three years.
More information is available in the press release.
A number of changes were made to the Reproducible Builds website and documentation this month, including Chris Lamb adding a redirect from /projects/ to /who/ in order to keep old or archived links working [], Jelle van der Waa added a Rust programming language example for SOURCE_DATE_EPOCH [][] and Mattia Rizzolo included Protocol Labs amongst our project-level sponsors [].
Debian
There was a large amount of reproducibility work taking place within Debian this month:
The nfft source package was removed from the archive, and now all packages in Debian bookworm now have a corresponding .buildinfo file. This can be confirmed and tracked on the associated page on thetests.reproducible-builds.org site.
Vagrant Cascadian announced on our mailing list an informal online sprint to help clear the huge backlog of reproducible builds patches submitted by performing NMU (Non-Maintainer Uploads). The first such sprint took place on September 22nd with the following results:
Holger Levsen:
Mailed #1010957 in man-db asking for an update and whether to remove the patch tag for now. This was subsequently removed and the maintainer started to address the issue.
Emailed #1017372 in plymouth and asked for the maintainer s opinion on the patch. This resulted in the maintainer improving Vagrant s original patch (and uploading it) as well as filing an issue upstream.
The plan is to repeat these sprints every two weeks, with the next taking place on Thursday October 6th at 16:00 UTC on the #debian-reproducible IRC channel.
Roland Clobus posted his 13th update of the status of reproducible Debian ISO images on our mailing list. During the last month, Roland ensured that the live images are now automatically fed to openQA for automated testing after they have been shown to be reproducible. Additionally Roland asked on the debian-devel mailing list about a way to determine the canonical timestamp of the Debian archive. []
Lastly, 44 reviews of Debian packages were added, 91 were updated and 17 were removed this month adding to our knowledge about identified issues. A number of issue types have been updated too, including the descriptions of cmake_rpath_contains_build_path [], nondeterministic_version_generated_by_python_param [] and timestamps_in_documentation_generated_by_org_mode []. Furthermore, two new issue types were created: build_path_used_to_determine_version_or_package_name [] and captures_build_path_via_cmake_variables [].
Other distributions
In openSUSE, Bernhard M. Wiedemann published his usual openSUSE monthly report.
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 222 and 223 to Debian, as well as made the following changes:
The cbfstools utility is now provided in Debian via the coreboot-utils package so we can enable that functionality within Debian. []
Fixed the try.diffoscope.org service by addressing a compatibility issue between glibc/seccomp that was preventing the Docker-contained diffoscope instance from spawning any external processes whatsoever []. I also updated the requirements.txt file, as some of the specified packages were no longer available [][].
In addition Jelle van der Waa added support for file version 5.43 [] and Mattia Rizzolo updated the packaging:
Also include coreboot-utils in the Build-Depends and Test-Depends fields so that it is available for tests. []
Use pep517 and pip to load the requirements. []
Remove packages in Breaks/Replaces that have been obsoleted since the release of Debian bullseye. []
Reprotestreprotest is our end-user tool to build the same source code twice in widely and deliberate different environments, and checking whether the binaries produced by the builds have any differences. This month, reprotest version 0.7.22 was uploaded to Debian unstable by Holger Levsen, which included the following changes by Philip Hands:
Actually ensure that the setarch(8) utility can actually execute before including an architecture to test. []
Include all files matching *.*deb in the default artifact_pattern in order to archive all results of the build. []
Emit an error when building the Debian package if the Debian packaging version does not patch the Python version of reprotest. []
Remove an unneeded invocation of the head(1) utility. []
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. This month, however, the following changes were made:
Holger Levsen:
Add a job to build reprotest from Git [] and use the correct Git branch when building it [].
Mattia Rizzolo:
Enable syncing of results from building live Debian ISO images. []
Use scp -p in order to preserve modification times when syncing live ISO images. []
Apply the shellcheck shell script analysis tool. []
In a build node wrapper script, remove some debugging code which was messing up calling scp(1) correctly [] and consquently add support to use both scp -p and regular scp [].
Roland Clobus:
Track and handle the case where the Debian archive gets updated between two live image builds. []
Remove a call to sudo(1) as it is not (or no longer) required to delete old live-build results. []
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Hello everyone. I am back to bringing KDE to your desktops in a variety of formats. I am always working on Debian packages, but now I will be working diligently to get these packages in Debian proper. Along with Debian packaging, I will be working on getting KDE into a variety of new packaging formats that are self contained packages of awesomeness. These formats are Snaps, Appimages and Flatpacks. I am starting with Snaps because I started the effort many years ago, but didn t have the time to keep them up. As such, they are in a sad state, so I am working hard with Jonathan and ppd to get them back in shape. Keep an eye out in your favorite store for shiny new apps from KDE!
https://snapcraft.io/search?q=KDEhttps://www.appimagehub.com/find?search=KDEhttps://flathub.org/apps/search/KDE
Our latest snap releases can be found here:
Welcome to the August 2022 report from the Reproducible Builds project! In these reports we outline the most important things that we have been up to over the past month. As a quick recap, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries. The motivation behind the reproducible builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised.
As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Community news
As announced last month, registration is currently open for our in-person summit this year which is due to be held between November 1st November 3rd. The event will take place in Venice (Italy). Very soon we intend to pick a venue reachable via the train station and an international airport. However, the precise venue will depend on the number of attendees. Please see the announcement email for information about how to register.
The US National Security Agency (NSA), Cybersecurity and Infrastructure Security Agency (CISA) and the Office of the Director of National Intelligence (ODNI) have released a document called Securing the Software Supply Chain: Recommended Practices Guide for Developers (PDF) as part of their Enduring Security Framework (ESF) work.
The document expressly recommends having reproducible builds as part of advanced recommended mitigations, along with hermetic builds. Page 31 (page 35 in the PDF) says:
Reproducible builds provide additional protection and validation against attempts to compromise build systems. They ensure the binary products of each build system match: i.e., they are built from the same source, regardless of variable metadata such as the order of input files, timestamps, locales, and paths. Reproducible builds are those where re-running the build steps with identical input artifacts results in bit-for-bit identical output. Builds that cannot meet this must provide a justification why the build cannot be made reproducible.
The full press release is available online.
On our mailing list this month, Marc Prud hommeaux posted a feature request for diffoscope which additionally outlines a project called The App Fair, an autonomous distribution network of free and open-source macOS and iOS applications, where validated apps are then signed and submitted for publication .
Author/blogger Cory Doctorow posted published a provocative blog post this month titled Your computer is tormented by a wicked god . Touching on Ken Thompson s famous talk, Reflections on Trusting Trust , the early goals of Secure Computing and UEFI firmware interfaces:
This is the core of a two-decade-old debate among security people, and it s one that the benevolent God faction has consistently had the upper hand in. They re the curated computing advocates who insist that preventing you from choosing an alternative app store or side-loading a program is for your own good because if it s possible for you to override the manufacturer s wishes, then malicious software may impersonate you to do so, or you might be tricked into doing so. [..] This benevolent dictatorship model only works so long as the dictator is both perfectly benevolent and perfectly competent. We know the dictators aren t always benevolent. [ ] But even if you trust a dictator s benevolence, you can t trust in their perfection. Everyone makes mistakes. Benevolent dictator computing works well, but fails badly. Designing a computer that intentionally can t be fully controlled by its owner is a nightmare, because that is a computer that, once compromised, can attack its owner with impunity.
Debian
In Debian this month, the essential and required package sets became 100% reproducible in Debian bookworm on the amd64 and arm64 architectures. These two subsets of the full Debian archive refer to Debian package priority levels as described in the 2.5 Priorities section of the Debian Policy there is no canonical minimal installation package set in Debian due to its diverse methods of installation.
As it happens, these package sets are not reproducible on the i386 architecture because the ncurses package on that architecture is not yet reproducible, and the sed package currently fails to build from source on armhf too. The full list of reproducible packages within these package sets can be viewed within our QA system, such as on the page of required packages in amd64 and the list of essential packages on arm64, both for Debian bullseye.
It recently has become very easy to install reproducible Debian Docker containers using podman on Debian bullseye:
The (pre-built) image used is itself built using debuerrotype, as explained on docker.debian.net. This page also details how to build the image yourself and what checksums are expected if you do so.
Related to this, it has also become straightforward to reproducibly bootstrap Debian using mmdebstrap, a replacement for the usual debootstrap tool to create Debian root filesystems:
This works for (at least) Debian unstable, bullseye and bookworm, and is tested automatically by a number of QA jobs set up by Holger Levsen (unstable, bookworm and bullseye)
Work has also taken place to ensure that the canonical debootstrap and cdebootstrap tools are also capable of bootstrapping Debian reproducibly, although it currently requires a few extra steps:
Clamping the modification time of files that are newer than $SOURCE_DATE_EPOCH to be not greater than SOURCE_DATE_EPOCH.
Deleting a few files. For debootstrap, this requires the deletion of /etc/machine-id, /var/cache/ldconfig/aux-cache, /var/log/dpkg.log, /var/log/alternatives.log and /var/log/bootstrap.log, and for cdebootstrap we also need to delete the /var/log/apt/history.log and /var/log/apt/term.log files as well.
This process works at least for unstable, bullseye and bookworm and is now being tested automatically by a number of QA jobs setup by Holger Levsen [][][][][][]. As part of this work, Holger filed two bugs to request a better initialisation of the /etc/machine-id file in both debootstrap [] and cdebootstrap [].
Elsewhere in Debian, 131 reviews of Debian packages were added, 20 were updated and 27 were removed this month, adding to our extensive knowledge about identified issues. Chris Lamb added a number of issue types, including: randomness_in_browserify_output [], haskell_abi_hash_differences [], nondeterministic_ids_in_html_output_generated_by_python_sphinx_panels []. Lastly, Mattia Rizzolo removed the deterministic flag from the captures_kernel_variant flag [].
Ignoring the pesky unknown packages, it is more like ~93% reproducibleand ~7% unreproducible... that feels a bit better to me!These numbers wander around over time, mostly due to packages movingback into an "unknown" state while the build farms catch up with eachother... although the above numbers seem to have been pretty consistentover the last few days.
The post itself contains a lot more details, including a brief discussion of tooling.
Elsewhere in GNU Guix, however, Vagrant updated a number of packages such as itpp [], perl-class-methodmaker [], libnet [], directfb [] and mm-common [], as well as updated the version of reprotest to 0.7.21 [].
In openSUSE, Bernhard M. Wiedemann published his usual openSUSE monthly report.
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 220 and 221 to Debian, as well as made the following changes:
Update external_tools.py to reflect changes to xxd and the vim-common package. []
Depend on the dedicated xxd package now, not the vim-common package. []
Don t crash if we can open a PDF file using the PyPDF library, but cannot subsequently parse the annotations within. []
In addition, Vagrant Cascadian updated diffoscope in GNU Guix, first to to version 220 [] and later to 221 [].
Community news
The Reproducible Builds project aims to fix as many currently-unreproducible packages as possible as well as to send all of our patches upstream wherever appropriate. This month we created a number of patches, including:
Bernhard M. Wiedemann:
at-spi-sharp (build failure when build on a multiprocessor machine).
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
Debian-related changes:
Temporarily add Debian unstabledeb-src lines to enable test builds a Non-maintainer Upload (NMU) campaign targeting 708 sources without .buildinfo files found in Debian unstable, including 475 in bookworm. [][]
Correctly deal with the Debian Edu packages not being installable. []
Finally, stop scheduling stretch. []
Make sure all Ubuntu nodes have the linux-image-generic kernel package installed. []
Only report the first uninstallable package set. []
Show new bootstrap jobs. [] and debian-live jobs. [] in the job health view.
Fix regular expression to detect various zombie jobs. []
New jobs:
Add a new job to test reproducibility of mmdebstrap bootstrapping tool. [][][][]
Run our new mmdebstrap job remotely [][]
Improve the output of the mmdebstrap job. [][][]
Adjust the mmdebstrap script to additionally support debootstrap as well. [][][]
Work around mmdebstrap and debootstrap keeping logfiles within their artifacts. [][][]
Add support for testing cdebootstrap too and add such a job for unstable. [][][]
Use a reproducible value for SOURCE_DATE_EPOCH for all our new bootstrap jobs. []
Misc changes:
Send the create_meta_pkg_sets notification to #debian-reproducible-changes instead of #debian-reproducible. []
In addition, Roland Clobus re-enabled the tests for live-build images [] and added a feature where the build would retry instead of give up when the archive was synced whilst building an ISO [], and Vagrant Cascadian added logging to report the current target of the /bin/sh symlink [].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Inspired by several others (such as Alex Schroeder s post and Szcze uja s prompt), as well as a desire to get this down for my kids, I figure it s time to write a bit about living through the PC and Internet revolution where I did: outside a tiny town in rural Kansas. And, as I ve been back in that same area for the past 15 years, I reflect some on the challenges that continue to play out.
Although the stories from the others were primarily about getting online, I want to start by setting some background. Those of you that didn t grow up in the same era as I did probably never realized that a typical business PC setup might cost $10,000 in today s dollars, for instance. So let me start with the background.
Nothing was easy
This story begins in the 1980s. Somewhere around my Kindergarten year of school, around 1985, my parents bought a TRS-80 Color Computer 2 (aka CoCo II). It had 64K of RAM and used a TV for display and sound.
This got you the computer. It didn t get you any disk drive or anything, no joysticks (required by a number of games). So whenever the system powered down, or it hung and you had to power cycle it a frequent event you d lose whatever you were doing and would have to re-enter the program, literally by typing it in.
The floppy drive for the CoCo II cost more than the computer, and it was quite common for people to buy the computer first and then the floppy drive later when they d saved up the money for that.
I particularly want to mention that computers then didn t come with a modem. What would be like buying a laptop or a tablet without wifi today. A modem, which I ll talk about in a bit, was another expensive accessory. To cobble together a system in the 80s that was capable of talking to others with persistent storage (floppy, or hard drive), screen, keyboard, and modem would be quite expensive. Adjusted for inflation, if you re talking a PC-style device (a clone of the IBM PC that ran DOS), this would easily be more expensive than the Macbook Pros of today.
Few people back in the 80s had a computer at home. And the portion of those that had even the capability to get online in a meaningful way was even smaller.
Eventually my parents bought a PC clone with 640K RAM and dual floppy drives. This was primarily used for my mom s work, but I did my best to take it over whenever possible. It ran DOS and, despite its monochrome screen, was generally a more capable machine than the CoCo II. For instance, it supported lowercase. (I m not even kidding; the CoCo II pretty much didn t.) A while later, they purchased a 32MB hard drive for it what luxury!
Just getting a machine to work wasn t easy. Say you d bought a PC, and then bought a hard drive, and a modem. You didn t just plug in the hard drive and it would work. You would have to fight it every step of the way. The BIOS and DOS partition tables of the day used a cylinder/head/sector method of addressing the drive, and various parts of that those addresses had too few bits to work with the big drives of the day above 20MB. So you would have to lie to the BIOS and fdisk in various ways, and sort of work out how to do it for each drive. For each peripheral serial port, sound card (in later years), etc., you d have to set jumpers for DMA and IRQs, hoping not to conflict with anything already in the system. Perhaps you can now start to see why USB and PCI were so welcomed.
Sharing and finding resources
Despite the two computers in our home, it wasn t as if software written on one machine just ran on another. A lot of software for PC clones assumed a CGA color display. The monochrome HGC in our PC wasn t particularly compatible. You could find a TSR program to emulate the CGA on the HGC, but it wasn t particularly stable, and there s only so much you can do when a program that assumes color displays on a monitor that can only show black, dark amber, or light amber.
So I d periodically get to use other computers most commonly at an office in the evening when it wasn t being used.
There were some local computer clubs that my dad took me to periodically. Software was swapped back then; disks copied, shareware exchanged, and so forth. For me, at least, there was no online to download software from, and selling software over the Internet wasn t a thing at all.
Three Different Worlds
There were sort of three different worlds of computing experience in the 80s:
Home users. Initially using a wide variety of software from Apple, Commodore, Tandy/RadioShack, etc., but eventually coming to be mostly dominated by IBM PC clones
Small and mid-sized business users. Some of them had larger minicomputers or small mainframes, but most that I had contact with by the early 90s were standardized on DOS-based PCs. More advanced ones had a network running Netware, most commonly. Networking hardware and software was generally too expensive for home users to use in the early days.
Universities and large institutions. These are the places that had the mainframes, the earliest implementations of TCP/IP, the earliest users of UUCP, and so forth.
The difference between the home computing experience and the large institution experience were vast. Not only in terms of dollars the large institution hardware could easily cost anywhere from tens of thousands to millions of dollars but also in terms of sheer resources required (large rooms, enormous power circuits, support staff, etc). Nothing was in common between them; not operating systems, not software, not experience. I was never much aware of the third category until the differences started to collapse in the mid-90s, and even then I only was exposed to it once the collapse was well underway.
You might say to me, Well, Google certainly isn t running what I m running at home! And, yes of course, it s different. But fundamentally, most large datacenters are running on x86_64 hardware, with Linux as the operating system, and a TCP/IP network. It s a different scale, obviously, but at a fundamental level, the hardware and operating system stack are pretty similar to what you can readily run at home. Back in the 80s and 90s, this wasn t the case. TCP/IP wasn t even available for DOS or Windows until much later, and when it was, it was a clunky beast that was difficult.
One of the things Kevin Driscoll highlights in his book called Modem World see my short post about it is that the history of the Internet we usually receive is focused on case 3: the large institutions. In reality, the Internet was and is literally a network of networks. Gateways to and from Internet existed from all three kinds of users for years, and while TCP/IP ultimately won the battle of the internetworking protocol, the other two streams of users also shaped the Internet as we now know it. Like many, I had no access to the large institution networks, but as I ve been reflecting on my experiences, I ve found a new appreciation for the way that those of us that grew up with primarily home PCs shaped the evolution of today s online world also.
An Era of Scarcity
I should take a moment to comment about the cost of software back then. A newspaper article from 1985 comments that WordPerfect, then the most powerful word processing program, sold for $495 (or $219 if you could score a mail order discount). That s $1360/$600 in 2022 money. Other popular software, such as Lotus 1-2-3, was up there as well. If you were to buy a new PC clone in the mid to late 80s, it would often cost $2000 in 1980s dollars. Now add a printer a low-end dot matrix for $300 or a laser for $1500 or even more. A modem: another $300. So the basic system would be $3600, or $9900 in 2022 dollars. If you wanted a nice printer, you re now pushing well over $10,000 in 2022 dollars.
You start to see one barrier here, and also why things like shareware and piracy if it was indeed even recognized as such were common in those days.
So you can see, from a home computer setup (TRS-80, Commodore C64, Apple ][, etc) to a business-class PC setup was an order of magnitude increase in cost. From there to the high-end minis/mainframes was another order of magnitude (at least!) increase. Eventually there was price pressure on the higher end and things all got better, which is probably why the non-DOS PCs lasted until the early 90s.
Increasing Capabilities
My first exposure to computers in school was in the 4th grade, when I would have been about 9. There was a single Apple ][ machine in that room. I primarily remember playing Oregon Trail on it. The next year, the school added a computer lab. Remember, this is a small rural area, so each graduating class might have about 25 people in it; this lab was shared by everyone in the K-8 building. It was full of some flavor of IBM PS/2 machines running DOS and Netware. There was a dedicated computer teacher too, though I think she was a regular teacher that was given somewhat minimal training on computers. We were going to learn typing that year, but I did so well on the very first typing program that we soon worked out that I could do programming instead. I started going to school early these machines were far more powerful than the XT at home and worked on programming projects there.
Eventually my parents bought me a Gateway 486SX/25 with a VGA monitor and hard drive. Wow! This was a whole different world. It may have come with Windows 3.0 or 3.1 on it, but I mainly remember running OS/2 on that machine. More on that below.
Programming
That CoCo II came with a BASIC interpreter in ROM. It came with a large manual, which served as a BASIC tutorial as well. The BASIC interpreter was also the shell, so literally you could not use the computer without at least a bit of BASIC.
Once I had access to a DOS machine, it also had a basic interpreter: GW-BASIC. There was a fair bit of software written in BASIC at the time, but most of the more advanced software wasn t. I wondered how these .EXE and .COM programs were written. I could find vague references to DEBUG.EXE, assemblers, and such. But it wasn t until I got a copy of Turbo Pascal that I was able to do that sort of thing myself. Eventually I got Borland C++ and taught myself C as well. A few years later, I wanted to try writing GUI programs for Windows, and bought Watcom C++ much cheaper than the competition, and it could target Windows, DOS (and I think even OS/2).
Notice that, aside from BASIC, none of this was free, and none of it was bundled. You couldn t just download a C compiler, or Python interpreter, or whatnot back then. You had to pay for the ability to write any kind of serious code on the computer you already owned.
The Microsoft Domination
Microsoft came to dominate the PC landscape, and then even the computing landscape as a whole. IBM very quickly lost control over the hardware side of PCs as Compaq and others made clones, but Microsoft has managed in varying degrees even to this day to keep a stranglehold on the software, and especially the operating system, side. Yes, there was occasional talk of things like DR-DOS, but by and large the dominant platform came to be the PC, and if you had a PC, you ran DOS (and later Windows) from Microsoft.
For awhile, it looked like IBM was going to challenge Microsoft on the operating system front; they had OS/2, and when I switched to it sometime around the version 2.1 era in 1993, it was unquestionably more advanced technically than the consumer-grade Windows from Microsoft at the time. It had Internet support baked in, could run most DOS and Windows programs, and had introduced a replacement for the by-then terrible FAT filesystem: HPFS, in 1988. Microsoft wouldn t introduce a better filesystem for its consumer operating systems until Windows XP in 2001, 13 years later. But more on that story later.
Free Software, Shareware, and Commercial Software
I ve covered the high cost of software already. Obviously $500 software wasn t going to sell in the home market. So what did we have?
Mainly, these things:
Public domain software. It was free to use, and if implemented in BASIC, probably had source code with it too.
Shareware
Commercial software (some of it from small publishers was a lot cheaper than $500)
Let s talk about shareware. The idea with shareware was that a company would release a useful program, sometimes limited. You were encouraged to register , or pay for, it if you liked it and used it. And, regardless of whether you registered it or not, were told please copy! Sometimes shareware was fully functional, and registering it got you nothing more than printed manuals and an easy conscience (guilt trips for not registering weren t necessarily very subtle). Sometimes unregistered shareware would have a nag screen a delay of a few seconds while they told you to register. Sometimes they d be limited in some way; you d get more features if you registered. With games, it was popular to have a trilogy, and release the first episode inevitably ending with a cliffhanger as shareware, and the subsequent episodes would require registration. In any event, a lot of software people used in the 80s and 90s was shareware. Also pirated commercial software, though in the earlier days of computing, I think some people didn t even know the difference.
Notice what s missing: Free Software / FLOSS in the Richard Stallman sense of the word. Stallman lived in the big institution world after all, he worked at MIT and what he was doing with the Free Software Foundation and GNU project beginning in 1983 never really filtered into the DOS/Windows world at the time. I had no awareness of it even existing until into the 90s, when I first started getting some hints of it as a port of gcc became available for OS/2. The Internet was what really brought this home, but I m getting ahead of myself.
I want to say again: FLOSS never really entered the DOS and Windows 3.x ecosystems. You d see it make a few inroads here and there in later versions of Windows, and moreso now that Microsoft has been sort of forced to accept it, but still, reflect on its legacy. What is the software market like in Windows compared to Linux, even today?
Now it is, finally, time to talk about connectivity!
Getting On-Line
What does it even mean to get on line? Certainly not connecting to a wifi access point. The answer is, unsurprisingly, complex. But for everyone except the large institutional users, it begins with a telephone.
The telephone system
By the 80s, there was one communication network that already reached into nearly every home in America: the phone system. Virtually every household (note I don t say every person) was uniquely identified by a 10-digit phone number. You could, at least in theory, call up virtually any other phone in the country and be connected in less than a minute.
But I ve got to talk about cost. The way things worked in the USA, you paid a monthly fee for a phone line. Included in that monthly fee was unlimited local calling. What is a local call? That was an extremely complex question. Generally it meant, roughly, calling within your city. But of course, as you deal with things like suburbs and cities growing into each other (eg, the Dallas-Ft. Worth metroplex), things got complicated fast. But let s just say for simplicity you could call others in your city.
What about calling people not in your city? That was long distance , and you paid often hugely by the minute for it. Long distance rates were difficult to figure out, but were generally most expensive during business hours and cheapest at night or on weekends. Prices eventually started to come down when competition was introduced for long distance carriers, but even then you often were stuck with a single carrier for long distance calls outside your city but within your state. Anyhow, let s just leave it at this: local calls were virtually free, and long distance calls were extremely expensive.
Getting a modem
I remember getting a modem that ran at either 1200bps or 2400bps. Either way, quite slow; you could often read even plain text faster than the modem could display it. But what was a modem?
A modem hooked up to a computer with a serial cable, and to the phone system. By the time I got one, modems could automatically dial and answer. You would send a command like ATDT5551212 and it would dial 555-1212. Modems had speakers, because often things wouldn t work right, and the telephone system was oriented around speech, so you could hear what was happening. You d hear it wait for dial tone, then dial, then hopefully the remote end would ring, a modem there would answer, you d hear the screeching of a handshake, and eventually your terminal would say CONNECT 2400. Now your computer was bridged to the other; anything going out your serial port was encoded as sound by your modem and decoded at the other end, and vice-versa.
But what, exactly, was the other end?
It might have been another person at their computer. Turn on local echo, and you can see what they did. Maybe you d send files to each other. But in my case, the answer was different: PC Magazine.
PC Magazine and CompuServe
Starting around 1986 (so I would have been about 6 years old), I got to read PC Magazine. My dad would bring copies that were being discarded at his office home for me to read, and I think eventually bought me a subscription directly. This was not just a standard magazine; it ran something like 350-400 pages an issue, and came out every other week. This thing was a monster. It had reviews of hardware and software, descriptions of upcoming technologies, pages and pages of ads (that often had some degree of being informative to them). And they had sections on programming. Many issues would talk about BASIC or Pascal programming, and there d be a utility in most issues. What do I mean by a utility in most issues ? Did they include a floppy disk with software?
No, of course not. There was a literal program listing printed in the magazine. If you wanted the utility, you had to type it in. And a lot of them were written in assembler, so you had to have an assembler. An assembler, of course, was not free and I didn t have one. Or maybe they wrote it in Microsoft C, and I had Borland C, and (of course) they weren t compatible. Sometimes they would list the program sort of in binary: line after line of a BASIC program, with lines like 64, 193, 253, 0, 53, 0, 87 that you would type in for hours, hopefully correctly. Running the BASIC program would, if you got it correct, emit a .COM file that you could then run. They did have a rudimentary checksum system built in, but it wasn t even a CRC, so something like swapping two numbers you d never notice except when the program would mysteriously hang.
Eventually they teamed up with CompuServe to offer a limited slice of CompuServe for the purpose of downloading PC Magazine utilities. This was called PC MagNet. I am foggy on the details, but I believe that for a time you could connect to the limited PC MagNet part of CompuServe for free (after the cost of the long-distance call, that is) rather than paying for CompuServe itself (because, OF COURSE, that also charged you per the minute.) So in the early days, I would get special permission from my parents to place a long distance call, and after some nerve-wracking minutes in which we were aware every minute was racking up charges, I could navigate the menus, download what I wanted, and log off immediately.
I still, incidentally, mourn what PC Magazine became. As with computing generally, it followed the mass market. It lost its deep technical chops, cut its programming columns, stopped talking about things like how SCSI worked, and so forth. By the time it stopped printing in 2009, it was no longer a square-bound 400-page beheamoth, but rather looked more like a copy of Newsweek, but with less depth.
Continuing with CompuServe
CompuServe was a much larger service than just PC MagNet. Eventually, our family got a subscription. It was still an expensive and scarce resource; I d call it only after hours when the long-distance rates were cheapest. Everyone had a numerical username separated by commas; mine was 71510,1421. CompuServe had forums, and files. Eventually I would use TapCIS to queue up things I wanted to do offline, to minimize phone usage online.
CompuServe eventually added a gateway to the Internet. For the sum of somewhere around $1 a message, you could send or receive an email from someone with an Internet email address! I remember the thrill of one time, as a kid of probably 11 years, sending a message to one of the editors of PC Magazine and getting a kind, if brief, reply back!
But inevitably I had
The Godzilla Phone Bill
Yes, one month I became lax in tracking my time online. I ran up my parents phone bill. I don t remember how high, but I remember it was hundreds of dollars, a hefty sum at the time. As I watched Jason Scott s BBS Documentary, I realized how common an experience this was. I think this was the end of CompuServe for me for awhile.
Toll-Free Numbers
I lived near a town with a population of 500. Not even IN town, but near town. The calling area included another town with a population of maybe 1500, so all told, there were maybe 2000 people total I could talk to with a local call though far fewer numbers, because remember, telephones were allocated by the household. There was, as far as I know, zero modems that were a local call (aside from one that belonged to a friend I met in around 1992). So basically everything was long-distance.
But there was a special feature of the telephone network: toll-free numbers. Normally when calling long-distance, you, the caller, paid the bill. But with a toll-free number, beginning with 1-800, the recipient paid the bill. These numbers almost inevitably belonged to corporations that wanted to make it easy for people to call. Sales and ordering lines, for instance. Some of these companies started to set up modems on toll-free numbers. There were few of these, but they existed, so of course I had to try them!
One of them was a company called PennyWise that sold office supplies. They had a toll-free line you could call with a modem to order stuff. Yes, online ordering before the web! I loved office supplies. And, because I lived far from a big city, if the local K-Mart didn t have it, I probably couldn t get it. Of course, the interface was entirely text, but you could search for products and place orders with the modem. I had loads of fun exploring the system, and actually ordered things from them and probably actually saved money doing so. With the first order they shipped a monster full-color catalog. That thing must have been 500 pages, like the Sears catalogs of the day. Every item had a part number, which streamlined ordering through the modem.
Inbound FAXes
By the 90s, a number of modems became able to send and receive FAXes as well. For those that don t know, a FAX machine was essentially a special modem. It would scan a page and digitally transmit it over the phone system, where it would at least in the early days be printed out in real time (because the machines didn t have the memory to store an entire page as an image). Eventually, PC modems integrated FAX capabilities.
There still wasn t anything useful I could do locally, but there were ways I could get other companies to FAX something to me. I remember two of them.
One was for US Robotics. They had an on demand FAX system. You d call up a toll-free number, which was an automated IVR system. You could navigate through it and select various documents of interest to you: spec sheets and the like. You d key in your FAX number, hang up, and US Robotics would call YOU and FAX you the documents you wanted. Yes! I was talking to a computer (of a sorts) at no cost to me!
The New York Times also ran a service for awhile called TimesFax. Every day, they would FAX out a page or two of summaries of the day s top stories. This was pretty cool in an era in which I had no other way to access anything from the New York Times. I managed to sign up for TimesFax I have no idea how, anymore and for awhile I would get a daily FAX of their top stories. When my family got its first laser printer, I could them even print these FAXes complete with the gothic New York Times masthead. Wow! (OK, so technically I could print it on a dot-matrix printer also, but graphics on a 9-pin dot matrix is a kind of pain that is a whole other article.)
My own phone line
Remember how I discussed that phone lines were allocated per household? This was a problem for a lot of reasons:
Anybody that tried to call my family while I was using my modem would get a busy signal (unable to complete the call)
If anybody in the house picked up the phone while I was using it, that would degrade the quality of the ongoing call and either mess up or disconnect the call in progress. In many cases, that could cancel a file transfer (which wasn t necessarily easy or possible to resume), prompting howls of annoyance from me.
Generally we all had to work around each other
So eventually I found various small jobs and used the money I made to pay for my own phone line and my own long distance costs. Eventually I upgraded to a 28.8Kbps US Robotics Courier modem even! Yes, you heard it right: I got a job and a bank account so I could have a phone line and a faster modem. Uh, isn t that why every teenager gets a job?
Now my local friend and I could call each other freely at least on my end (I can t remember if he had his own phone line too). We could exchange files using HS/Link, which had the added benefit of allowing split-screen chat even while a file transfer is in progress. I m sure we spent hours chatting to each other keyboard-to-keyboard while sharing files with each other.
Technology in Schools
By this point in the story, we re in the late 80s and early 90s. I m still using PC-style OSs at home; OS/2 in the later years of this period, DOS or maybe a bit of Windows in the earlier years. I mentioned that they let me work on programming at school starting in 5th grade. It was soon apparent that I knew more about computers than anybody on staff, and I started getting pulled out of class to help teachers or administrators with vexing school problems. This continued until I graduated from high school, incidentally often to my enjoyment, and the annoyance of one particular teacher who, I must say, I was fine with annoying in this way.
That s not to say that there was institutional support for what I was doing. It was, after all, a small school. Larger schools might have introduced BASIC or maybe Logo in high school. But I had already taught myself BASIC, Pascal, and C by the time I was somewhere around 12 years old. So I wouldn t have had any use for that anyhow.
There were programming contests occasionally held in the area. Schools would send teams. My school didn t really send anybody, but I went as an individual. One of them was run by a local college (but for jr. high or high school students. Years later, I met one of the professors that ran it. He remembered me, and that day, better than I did. The programming contest had problems one could solve in BASIC or Logo. I knew nothing about what to expect going into it, but I had lugged my computer and screen along, and asked him, Can I write my solutions in C? He was, apparently, stunned, but said sure, go for it. I took first place that day, leading to some rather confused teams from much larger schools.
The Netware network that the school had was, as these generally were, itself isolated. There was no link to the Internet or anything like it. Several schools across three local counties eventually invested in a fiber-optic network linking them together. This built a larger, but still closed, network. Its primary purpose was to allow students to be exposed to a wider variety of classes at high schools. Participating schools had an ITV room , outfitted with cameras and mics. So students at any school could take classes offered over ITV at other schools. For instance, only my school taught German classes, so people at any of those participating schools could take German. It was an early Zoom room. But alongside the TV signal, there was enough bandwidth to run some Netware frames. By about 1995 or so, this let one of the schools purchase some CD-ROM software that was made available on a file server and could be accessed by any participating school. Nice! But Netware was mainly about file and printer sharing; there wasn t even a facility like email, at least not on our deployment.
BBSs
My last hop before the Internet was the BBS. A BBS was a computer program, usually ran by a hobbyist like me, on a computer with a modem connected. Callers would call it up, and they d interact with the BBS. Most BBSs had discussion groups like forums and file areas. Some also had games. I, of course, continued to have that most vexing of problems: they were all long-distance.
There were some ways to help with that, chiefly QWK and BlueWave. These, somewhat like TapCIS in the CompuServe days, let me download new message posts for reading offline, and queue up my own messages to send later. QWK and BlueWave didn t help with file downloading, though.
BBSs get networked
BBSs were an interesting thing. You d call up one, and inevitably somewhere in the file area would be a BBS list. Download the BBS list and you ve suddenly got a list of phone numbers to try calling. All of them were long distance, of course. You d try calling them at random and have a success rate of maybe 20%. The other 80% would be defunct; you might get the dreaded this number is no longer in service or the even more dreaded angry human answering the phone (and of course a modem can t talk to a human, so they d just get silence for probably the nth time that week). The phone company cared nothing about BBSs and recycled their numbers just as fast as any others.
To talk to various people, or participate in certain discussion groups, you d have to call specific BBSs. That s annoying enough in the general case, but even more so for someone paying long distance for it all, because it takes a few minutes to establish a connection to a BBS: handshaking, logging in, menu navigation, etc.
But BBSs started talking to each other. The earliest successful such effort was FidoNet, and for the duration of the BBS era, it remained by far the largest. FidoNet was analogous to the UUCP that the institutional users had, but ran on the much cheaper PC hardware. Basically, BBSs that participated in FidoNet would relay email, forum posts, and files between themselves overnight. Eventually, as with UUCP, by hopping through this network, messages could reach around the globe, and forums could have worldwide participation asynchronously, long before they could link to each other directly via the Internet. It was almost entirely volunteer-run.
Running my own BBS
At age 13, I eventually chose to set up my own BBS. It ran on my single phone line, so of course when I was dialing up something else, nobody could dial up me. Not that this was a huge problem; in my town of 500, I probably had a good 1 or 2 regular callers in the beginning.
In the PC era, there was a big difference between a server and a client. Server-class software was expensive and rare. Maybe in later years you had an email client, but an email server would be completely unavailable to you as a home user. But with a BBS, I could effectively run a server. I even ran serial lines in our house so that the BBS could be connected from other rooms! Since I was running OS/2, the BBS didn t tie up the computer; I could continue using it for other things.
FidoNet had an Internet email gateway. This one, unlike CompuServe s, was free. Once I had a BBS on FidoNet, you could reach me from the Internet using the FidoNet address. This didn t support attachments, but then email of the day didn t really, either.
Various others outside Kansas ran FidoNet distribution points. I believe one of them was mgmtsys; my memory is quite vague, but I think they offered a direct gateway and I would call them to pick up Internet mail via FidoNet protocols, but I m not at all certain of this.
Pros and Cons of the Non-Microsoft World
As mentioned, Microsoft was and is the dominant operating system vendor for PCs. But I left that world in 1993, and here, nearly 30 years later, have never really returned. I got an operating system with more technical capabilities than the DOS and Windows of the day, but the tradeoff was a much smaller software ecosystem. OS/2 could run DOS programs, but it ran OS/2 programs a lot better. So if I were to run a BBS, I wanted one that had a native OS/2 version limiting me to a small fraction of available BBS server software. On the other hand, as a fully 32-bit operating system, there started to be OS/2 ports of certain software with a Unix heritage; most notably for me at the time, gcc. At some point, I eventually came across the RMS essays and started to be hooked.
Internet: The Hunt Begins
I certainly was aware that the Internet was out there and interesting. But the first problem was: how the heck do I get connected to the Internet?
Learning Link and Gopher
ISPs weren t really a thing; the first one in my area (though still a long-distance call) started in, I think, 1994. One service that one of my teachers got me hooked up with was Learning Link. Learning Link was a nationwide collaboration of PBS stations and schools, designed to build on the educational mission of PBS. The nearest Learning Link station was more than a 3-hour drive away but critically, they had a toll-free access number, and my teacher convinced them to let me use it. I connected via a terminal program and a modem, like with most other things. I don t remember much about it, but I do remember a very important thing it had: Gopher. That was my first experience with Gopher.
Learning Link was hosted by a Unix derivative (Xenix), but it didn t exactly give everyone a shell. I seem to recall it didn t have open FTP access either. The Gopher client had FTP access at some point; I don t recall for sure if it did then. If it did, then when a Gopher server referred to an FTP server, I could get to it. (I am unclear at this point if I could key in an arbitrary FTP location, or knew how, at that time.) I also had email access there, but I don t recall exactly how; probably Pine. If that s correct, that would have dated my Learning Link access as no earlier than 1992.
I think my access time to Learning Link was limited. And, since the only way to get out on the Internet from there was Gopher and Pine, I was somewhat limited in terms of technology as well. I believe that telnet services, for instance, weren t available to me.
Computer labs
There was one place that tended to have Internet access: colleges and universities. In 7th grade, I participated in a program that resulted in me being invited to visit Duke University, and in 8th grade, I participated in National History Day, resulting in a trip to visit the University of Maryland. I probably sought out computer labs at both of those. My most distinct memory was finding my way into a computer lab at one of those universities, and it was full of NeXT workstations. I had never seen or used NeXT before, and had no idea how to operate it. I had brought a box of floppy disks, unaware that the DOS disks probably weren t compatible with NeXT.
Closer to home, a small college had a computer lab that I could also visit. I would go there in summer or when it wasn t used with my stack of floppies. I remember downloading disk images of FLOSS operating systems: FreeBSD, Slackware, or Debian, at the time. The hash marks from the DOS-based FTP client would creep across the screen as the 1.44MB disk images would slowly download. telnet was also available on those machines, so I could telnet to things like public-access Archie servers and libraries though not Gopher. Still, FTP and telnet access opened up a lot, and I learned quite a bit in those years.
Continuing the Journey
At some point, I got a copy of the Whole Internet User s Guide and Catalog, published in 1994. I still have it. If it hadn t already figured it out by then, I certainly became aware from it that Unix was the dominant operating system on the Internet. The examples in Whole Internet covered FTP, telnet, gopher all assuming the user somehow got to a Unix prompt. The web was introduced about 300 pages in; clearly viewed as something that wasn t page 1 material. And it covered the command-line www client before introducing the graphical Mosaic. Even then, though, the book highlighted Mosaic s utility as a front-end for Gopher and FTP, and even the ability to launch telnet sessions by clicking on links. But having a copy of the book didn t equate to having any way to run Mosaic. The machines in the computer lab I mentioned above all ran DOS and were incapable of running a graphical browser. I had no SLIP or PPP (both ways to run Internet traffic over a modem) connectivity at home. In short, the Web was something for the large institutional users at the time.
CD-ROMs
As CD-ROMs came out, with their huge (for the day) 650MB capacity, various companies started collecting software that could be downloaded on the Internet and selling it on CD-ROM. The two most popular ones were Walnut Creek CD-ROM and Infomagic. One could buy extensive Shareware and gaming collections, and then even entire Linux and BSD distributions. Although not exactly an Internet service per se, it was a way of bringing what may ordinarily only be accessible to institutional users into the home computer realm.
Free Software Jumps In
As I mentioned, by the mid 90s, I had come across RMS s writings about free software most probably his 1992 essay Why Software Should Be Free. (Please note, this is not a commentary on the more recently-revealed issues surrounding RMS, but rather his writings and work as I encountered them in the 90s.) The notion of a Free operating system not just in cost but in openness was incredibly appealing. Not only could I tinker with it to a much greater extent due to having source for everything, but it included so much software that I d otherwise have to pay for. Compilers! Interpreters! Editors! Terminal emulators! And, especially, server software of all sorts. There d be no way I could afford or run Netware, but with a Free Unixy operating system, I could do all that. My interest was obviously piqued. Add to that the fact that I could actually participate and contribute I was about to become hooked on something that I ve stayed hooked on for decades.
But then the question was: which Free operating system? Eventually I chose FreeBSD to begin with; that would have been sometime in 1995. I don t recall the exact reasons for that. I remember downloading Slackware install floppies, and probably the fact that Debian wasn t yet at 1.0 scared me off for a time. FreeBSD s fantastic Handbook far better than anything I could find for Linux at the time was no doubt also a factor.
The de Raadt Factor
Why not NetBSD or OpenBSD? The short answer is Theo de Raadt. Somewhere in this time, when I was somewhere between 14 and 16 years old, I asked some questions comparing NetBSD to the other two free BSDs. This was on a NetBSD mailing list, but for some reason Theo saw it and got a flame war going, which CC d me. Now keep in mind that even if NetBSD had a web presence at the time, it would have been minimal, and I would have not all that unusually for the time had no way to access it. I was certainly not aware of the, shall we say, acrimony between Theo and NetBSD. While I had certainly seen an online flamewar before, this took on a different and more disturbing tone; months later, Theo randomly emailed me under the subject SLIME saying that I was, well, SLIME . I seem to recall periodic emails from him thereafter reminding me that he hates me and that he had blocked me. (Disclaimer: I have poor email archives from this period, so the full details are lost to me, but I believe I am accurately conveying these events from over 25 years ago)
This was a surprise, and an unpleasant one. I was trying to learn, and while it is possible I didn t understand some aspect or other of netiquette (or Theo s personal hatred of NetBSD) at the time, still that is not a reason to flame a 16-year-old (though he would have had no way to know my age). This didn t leave any kind of scar, but did leave a lasting impression; to this day, I am particularly concerned with how FLOSS projects handle poisonous people. Debian, for instance, has come a long way in this over the years, and even Linus Torvalds has turned over a new leaf. I don t know if Theo has.
In any case, I didn t use NetBSD then. I did try it periodically in the years since, but never found it compelling enough to justify a large switch from Debian. I never tried OpenBSD for various reasons, but one of them was that I didn t want to join a community that tolerates behavior such as Theo s from its leader.
Moving to FreeBSD
Moving from OS/2 to FreeBSD was final. That is, I didn t have enough hard drive space to keep both. I also didn t have the backup capacity to back up OS/2 completely. My BBS, which ran Virtual BBS (and at some point also AdeptXBBS) was deleted and reincarnated in a different form. My BBS was a member of both FidoNet and VirtualNet; the latter was specific to VBBS, and had to be dropped. I believe I may have also had to drop the FidoNet link for a time. This was the biggest change of computing in my life to that point. The earlier experiences hadn t literally destroyed what came before. OS/2 could still run my DOS programs. Its command shell was quite DOS-like. It ran Windows programs. I was going to throw all that away and leap into the unknown.
I wish I had saved a copy of my BBS; I would love to see the messages I exchanged back then, or see its menu screens again. I have little memory of what it looked like. But other than that, I have no regrets. Pursuing Free, Unixy operating systems brought me a lot of enjoyment and a good career.
That s not to say it was easy. All the problems of not being in the Microsoft ecosystem were magnified under FreeBSD and Linux. In a day before EDID, monitor timings had to be calculated manually and you risked destroying your monitor if you got them wrong. Word processing and spreadsheet software was pretty much not there for FreeBSD or Linux at the time; I was therefore forced to learn LaTeX and actually appreciated that. Software like PageMaker or CorelDraw was certainly nowhere to be found for those free operating systems either. But I got a ton of new capabilities.
I mentioned the BBS didn t shut down, and indeed it didn t. I ran what was surely a supremely unique oddity: a free, dialin Unix shell server in the middle of a small town in Kansas. I m sure I provided things such as pine for email and some help text and maybe even printouts for how to use it. The set of callers slowly grew over the time period, in fact.
And then I got UUCP.
Enter UUCP
Even throughout all this, there was no local Internet provider and things were still long distance. I had Internet Email access via assorted strange routes, but they were all strange. And, I wanted access to Usenet. In 1995, it happened.
The local ISP I mentioned offered UUCP access. Though I couldn t afford the dialup shell (or later, SLIP/PPP) that they offered due to long-distance costs, UUCP s very efficient batched processes looked doable. I believe I established that link when I was 15, so in 1995.
I worked to register my domain, complete.org, as well. At the time, the process was a bit lengthy and involved downloading a text file form, filling it out in a precise way, sending it to InterNIC, and probably mailing them a check. Well I did that, and in September of 1995, complete.org became mine. I set up sendmail on my local system, as well as INN to handle the limited Usenet newsfeed I requested from the ISP. I even ran Majordomo to host some mailing lists, including some that were surprisingly high-traffic for a few-times-a-day long-distance modem UUCP link!
The modem client programs for FreeBSD were somewhat less advanced than for OS/2, but I believe I wound up using Minicom or Seyon to continue to dial out to BBSs and, I believe, continue to use Learning Link. So all the while I was setting up my local BBS, I continued to have access to the text Internet, consisting of chiefly Gopher for me.
Switching to Debian
I switched to Debian sometime in 1995 or 1996, and have been using Debian as my primary OS ever since. I continued to offer shell access, but added the WorldVU Atlantis menuing BBS system. This provided a return of a more BBS-like interface (by default; shell was still an uption) as well as some BBS door games such as LoRD and TradeWars 2002, running under DOS emulation.
I also continued to run INN, and ran ifgate to allow FidoNet echomail to be presented into INN Usenet-like newsgroups, and netmail to be gated to Unix email. This worked pretty well. The BBS continued to grow in these days, peaking at about two dozen total user accounts, and maybe a dozen regular users.
Dial-up access availability
I believe it was in 1996 that dial up PPP access finally became available in my small town. What a thrill! FINALLY! I could now FTP, use Gopher, telnet, and the web all from home. Of course, it was at modem speeds, but still.
(Strangely, I have a memory of accessing the Web using WebExplorer from OS/2. I don t know exactly why; it s possible that by this time, I had upgraded to a 486 DX2/66 and was able to reinstall OS/2 on the old 25MHz 486, or maybe something was wrong with the timeline from my memories from 25 years ago above. Or perhaps I made the occasional long-distance call somewhere before I ditched OS/2.)
Gopher sites still existed at this point, and I could access them using Netscape Navigator which likely became my standard Gopher client at that point. I don t recall using UMN text-mode gopher client locally at that time, though it s certainly possible I did.
The city
Starting when I was 15, I took computer science classes at Wichita State University. The first one was a class in the summer of 1995 on C++. I remember being worried about being good enough for it I was, after all, just after my HS freshman year and had never taken the prerequisite C class. I loved it and got an A! By 1996, I was taking more classes.
In 1996 or 1997 I stayed in Wichita during the day due to having more than one class. So, what would I do then but enjoy the computer lab? The CS dept. had two of them: one that had NCD X terminals connected to a pair of SunOS servers, and another one running Windows. I spent most of the time in the Unix lab with the NCDs; I d use Netscape or pine, write code, enjoy the University s fast Internet connection, and so forth.
In 1997 I had graduated high school and that summer I moved to Wichita to attend college. As was so often the case, I shut down the BBS at that time. It would be 5 years until I again dealt with Internet at home in a rural community.
By the time I moved to my apartment in Wichita, I had stopped using OS/2 entirely. I have no memory of ever having OS/2 there. Along the way, I had bought a Pentium 166, and then the most expensive piece of computing equipment I have ever owned: a DEC Alpha, which, of course, ran Linux.
ISDN
I must have used dialup PPP for a time, but I eventually got a job working for the ISP I had used for UUCP, and then PPP. While there, I got a 128Kbps ISDN line installed in my apartment, and they gave me a discount on the service for it. That was around 3x the speed of a modem, and crucially was always on and gave me a public IP. No longer did I have to use UUCP; now I got to host my own things! By at least 1998, I was running a web server on www.complete.org, and I had an FTP server going as well.
Even Bigger Cities
In 1999 I moved to Dallas, and there got my first broadband connection: an ADSL link at, I think, 1.5Mbps! Now that was something! But it had some reliability problems. I eventually put together a server and had it hosted at an acquantaince s place who had SDSL in his apartment. Within a couple of years, I had switched to various kinds of proper hosting for it, but that is a whole other article.
In Indianapolis, I got a cable modem for the first time, with even tighter speeds but prohibitions on running servers on it. Yuck.
Challenges
Being non-Microsoft continued to have challenges. Until the advent of Firefox, a web browser was one of the biggest. While Netscape supported Linux on i386, it didn t support Linux on Alpha. I hobbled along with various attempts at emulators, old versions of Mosaic, and so forth. And, until StarOffice was open-sourced as Open Office, reading Microsoft file formats was also a challenge, though WordPerfect was briefly available for Linux.
Over the years, I have become used to the Linux ecosystem. Perhaps I use Gimp instead of Photoshop and digikam instead of well, whatever somebody would use on Windows. But I get ZFS, and containers, and so much that isn t available there.
Yes, I know Apple never went away and is a thing, but for most of the time period I discuss in this article, at least after the rise of DOS, it was niche compared to the PC market.
Back to Kansas
In 2002, I moved back to Kansas, to a rural home near a different small town in the county next to where I grew up. Over there, it was back to dialup at home, but I had faster access at work. I didn t much care for this, and thus began a 20+-year effort to get broadband in the country. At first, I got a wireless link, which worked well enough in the winter, but had serious problems in the summer when the trees leafed out. Eventually DSL became available locally highly unreliable, but still, it was something. Then I moved back to the community I grew up in, a few miles from where I grew up. Again I got DSL a bit better. But after some years, being at the end of the run of DSL meant I had poor speeds and reliability problems. I eventually switched to various wireless ISPs, which continues to the present day; while people in cities can get Gbps service, I can get, at best, about 50Mbps. Long-distance fees are gone, but the speed disparity remains.
Concluding Reflections
I am glad I grew up where I did; the strong community has a lot of advantages I don t have room to discuss here. In a number of very real senses, having no local services made things a lot more difficult than they otherwise would have been. However, perhaps I could say that I also learned a lot through the need to come up with inventive solutions to those challenges. To this day, I think a lot about computing in remote environments: partially because I live in one, and partially because I enjoy visiting places that are remote enough that they have no Internet, phone, or cell service whatsoever. I have written articles like Tools for Communicating Offline and in Difficult Circumstances based on my own personal experience. I instinctively think about making protocols robust in the face of various kinds of connectivity failures because I experience various kinds of connectivity failures myself.
(Almost) Everything Lives On
In 2002, Gopher turned 10 years old. It had probably been about 9 or 10 years since I had first used Gopher, which was the first way I got on live Internet from my house. It was hard to believe. By that point, I had an always-on Internet link at home and at work. I had my Alpha, and probably also at least PCMCIA Ethernet for a laptop (many laptops had modems by the 90s also). Despite its popularity in the early 90s, less than 10 years after it came on the scene and started to unify the Internet, it was mostly forgotten.
And it was at that moment that I decided to try to resurrect it. The University of Minnesota finally released it under an Open Source license. I wrote the first new gopher server in years, pygopherd, and introduced gopher to Debian. Gopher lives on; there are now quite a few Gopher clients and servers out there, newly started post-2002. The Gemini protocol can be thought of as something akin to Gopher 2.0, and it too has a small but blossoming ecosystem.
Archie, the old FTP search tool, is dead though. Same for WAIS and a number of the other pre-web search tools. But still, even FTP lives on today.
And BBSs? Well, they didn t go away either. Jason Scott s fabulous BBS documentary looks back at the history of the BBS, while Back to the BBS from last year talks about the modern BBS scene. FidoNet somehow is still alive and kicking. UUCP still has its place and has inspired a whole string of successors. Some, like NNCP, are clearly direct descendents of UUCP. Filespooler lives in that ecosystem, and you can even see UUCP concepts in projects as far afield as Syncthing and Meshtastic. Usenet still exists, and you can now run Usenet over NNCP just as I ran Usenet over UUCP back in the day (which you can still do as well). Telnet, of course, has been largely supplanted by ssh, but the concept is more popular now than ever, as Linux has made ssh be available on everything from Raspberry Pi to Android.
And I still run a Gopher server, looking pretty much like it did in 2002.
This post also has a permanent home on my website, where it may be periodically updated.
Welcome to the July 2022 report from the Reproducible Builds project!
In our reports we attempt to outline the most relevant things that have been going on in the past month. As a brief introduction, the reproducible builds effort is concerned with ensuring no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Reproducible Builds summit 2022
Despite several delays, we are pleased to announce that registration is open for our in-person summit this year:
November 1st November 3rd
The event will happen in Venice (Italy). We intend to pick a venue reachable via the train station and an international airport. However, the precise venue will depend on the number of attendees.
Please see the announcement email for information about how to register.
Our attention was recently caught by a nice slide deck on the methods and tools for reproducible research in the R programming language. Among those, the talk mentions Guix, stating that it is for professional, sensitive applications that require ultimate reproducibility , which is probably a bit overkill for Reproducible Research . While we were flattered to see Guix suggested as good tool for reproducibility, the very notion that there s a kind of reproducibility that is ultimate and, essentially, impractical, is something that left us wondering: What kind of reproducibility do scientists need, if not the ultimate kind? Is reproducibility practical at all, or is it more of a horizon?
The post goes on to outlines the concept of reproducibility, situating examples within the context of the GNU Guix operating system.
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 218, 219 and 220 to Debian, as well as made the following changes:
Fix a regression introduced in version 207 where diffoscope would crash if one directory contained a directory that wasn t in the other. Thanks to Alderico Gallo for the testcase. []
Don t traceback if we encounter an invalid Unicode character in Haskell versioning headers. []
Santiago Torres-Arias announced a Call for Papers (CfP) for a new SCORED conference, an academic workshop around software supply chain security . As Santiago highlights, this new conference invites reviewers from industry, open source, governement and academia to review the papers [and] I think that this is super important to tackle the supply chain security task .
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, however, we submitted the following patches:
Reprotestreprotest is the Reproducible Builds project s end-user tool to build the same source code twice in widely and deliberate different environments, and checking whether the binaries produced by the builds have any differences. This month, the following changes were made:
Holger Levsen:
Uploaded version 0.7.21 to Debian unstable as well as mark 0.7.22 development in the repository [].
Make diffoscope dependency unversioned as the required version is met even in Debian buster. []
Revert an accidentally committed hunk. []
Mattia Rizzolo:
Apply a patch from Nick Rosbrook to not force the tests to run only against Python 3.9. []
Run the tests through pybuild in order to run them against all supported Python 3.x versions. []
Fix a deprecation warning in the setup.cfg file. []
Close a new Debian bug. []
Reproducible builds website
A number of changes were made to the Reproducible Builds website and documentation this month, including:
Add talk from FOSDEM 2015 presented by Holger and Lunar. []
Show date of presentations if we have them. [][]
Add my presentation from DebConf22 [] and from Debian Reunion Hamburg 2022 [].
Add dhole to the speakers of the DebConf15 talk. []
Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. []
Drop some Debian-related suggested ideas which are not really relevant anymore. []
Add a link to list of packages with patches ready to be NMUed. []
Mattia Rizzolo:
Add information about our upcoming event in Venice. [][][][]
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
Debian-related changes:
Create graphs displaying existing .buildinfo files per each Debian suite/arch. [][]
Fix a typo in the Debian dashboard. [][]
Fix some issues in the pkg-r package set definition. [][][]
Improve the builtin-pho HTML output. [][][][]
Temporarily disable all live builds as our snapshot mirror is offline. []
Automated node health checks:
Detect dpkg failures. []
Detect files with bad UNIX permissions. []
Relax a regular expression in order to detect Debian Live image build failures. []
Misc changes:
Test that FreeBSD virtual machine has been updated to version 13.1. []
Add a reminder about powercycling the armhf-architecture mst0X node. []
Fix a number of typos. [][]
Update documentation. [][]
Fix Munin monitoring configuration for some nodes. []
Fix the static IP address for a node. []
In addition, Vagrant Cascadian updated host keys for the cbxi4pro0 and wbq0 nodes [] and, finally, node maintenance was also performed by Mattia Rizzolo [] and Holger Levsen [][][].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
 Photo by Taylor Vick (Unsplash)
Photo by Taylor Vick (Unsplash)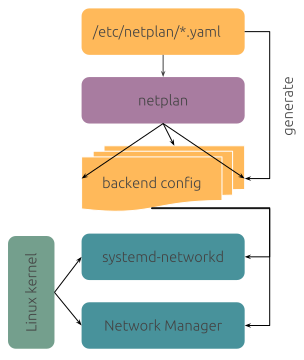 Design overview (netplan.io)
Design overview (netplan.io)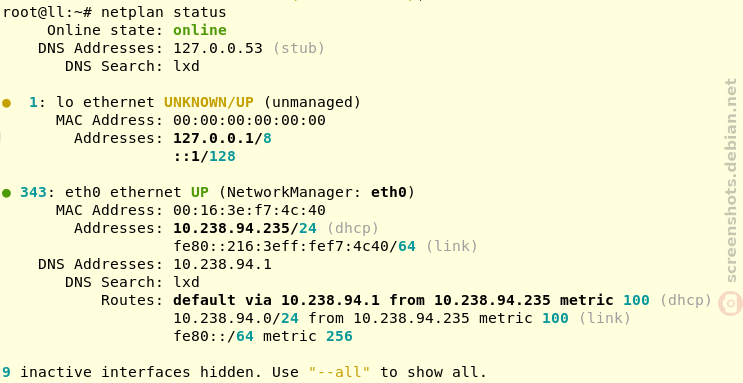 Netplan status (Debian)
Netplan status (Debian) I wrote the
I wrote the  Wrong sort of shim, but canned language bindings would be handy
Wrong sort of shim, but canned language bindings would be handy
 This is what I imagine it looks like inside these libraries
This is what I imagine it looks like inside these libraries















 This is the second part of how I build a read-only root setup for my router. You might want to read
This is the second part of how I build a read-only root setup for my router. You might want to read 
























 A first update to the recently-released package
A first update to the recently-released package 


















{kind=link}
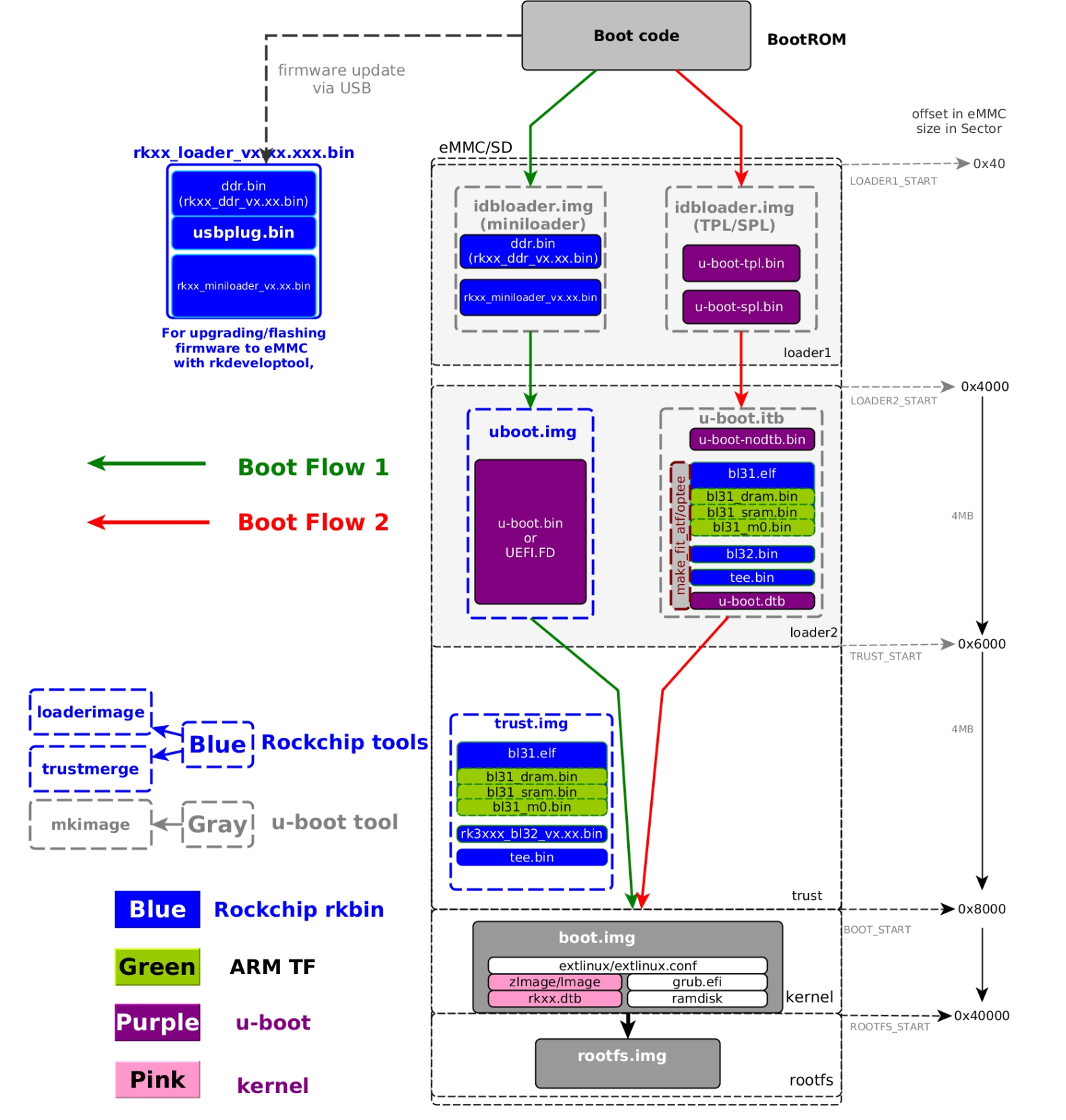{kind=link}